



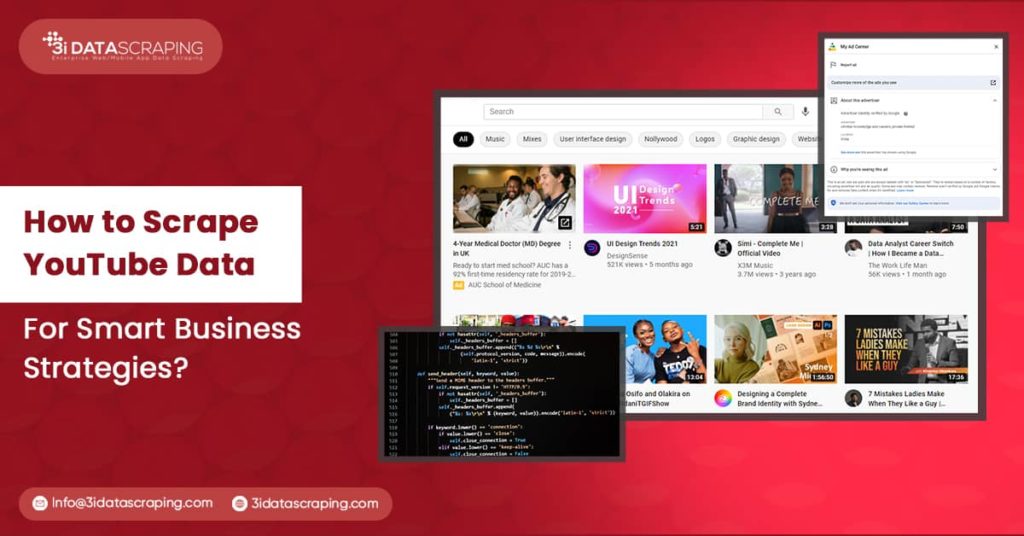
Most of the information on YouTube is accessible publicly, but it is crucial to avoid scraping activities that can harm the target website’s operations. Hold the ethical standards when you Scrape Data from YouTube by following the below principles:
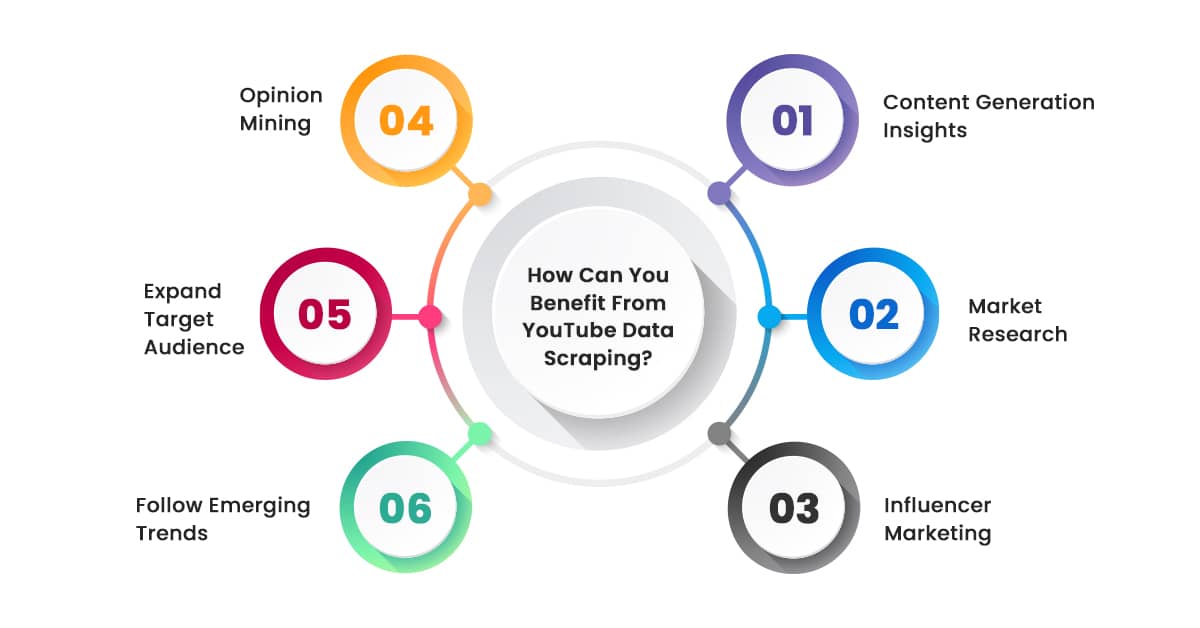
Being a top social media application that streams videos and relevant content, it is becoming an acceptable source for understanding entertaining and original content. Some of the incredible advantages are:
When you have the correct YouTube data, scraping tools will gather detailed datasets about content in different industries. Analyzing the content will give you valuable information about customers, marketing strategies, content posting, and other factors on YouTube.
A business can scrape data from YouTube to determine video titles, views, likes, comments, and shares. It can then use this data to focus on marketing campaigns, identify opportunities, and build new products.
Some seek influential content creators to collaborate or promote their services and products. Businesses can work on their brand awareness and scale to more significant locations.
This is also known as sentiment analysis, and it is used to extract customer views, whether negative, neutral, or positive. YouTube video details help you understand customer preferences and customize their solutions accordingly.
People use social media to share their opinions about various brands, services, and products. Collect such video information to respond instantly to complaints and find brand mentions. This helps you understand your services’ likes and dislikes so that you can make necessary changes for better user engagement.
Most social media algorithms rank based on user interactions, views, or likes. Understanding how your competitors perform and their position in YouTube search results is essential to determine our customer’s interests.
You can do multiple things with scraped data from YouTube effectively. Here are some approaches to handle post-scraping:
You are now well aware of the ethical methods used to scrape YouTube data. With bulk data updating every second, it is challenging for businesses to stay unique and follow trends. It is essential to maintain the right balance to ensure you are engaging with potential audiences and scaling efficiently.
Businesses are looking for data-driven results by scraping YouTube data. However, they are in a dilemma because they must find a reliable source that uses advanced technologies and ethical data scraping methods.
At 3iDataScraping, we have the expertise to provide hassle-free custom data scraping solutions that meet your expectations. We gather accurate data sets and share them in multiple formats that are easier to analyze.














info@3idatascraping.com

+1 832 251 7311

+49 175 8678468

+91 757 503 4565