3 Strong Reasons Why Consult A Professional Firm For Amazon Web Data Scraping
When crawling a completely big website, the real web scraping (analyzing as well as making demands HTML) ends up being a really small component of your program.
Our achievements in the field of business digital transformation.




When crawling a completely big website, the real web scraping (analyzing as well as making demands HTML) ends up being a really small component of your program. Rather, you invest a great deal of time identifying how you can maintain the whole crawl running efficiently and also successfully.
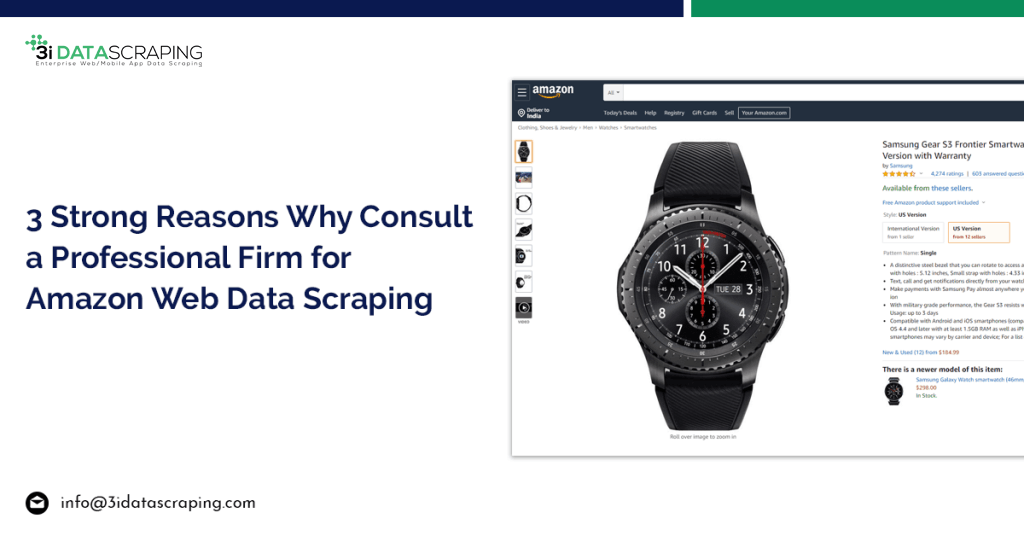
An introduction to Amazon.com Crawling
In its most basic type, web scraping has to do with making demands and also removing information from the action. For a tiny web scraping job, your code could be easy. You simply should discover a couple of patterns in the links as well as in the HTML action as well as you stay in business. It is one heck of a challenge when you’re attempting to draw over 1,000,000 items from the biggest e-commerce website on the earth.
High Performance is a must
When thinking of crawling anything greater than a couple of hundred web pages, you actually need to consider placing the pedal to the steel and also pressing your program up until it strikes the traffic jam of some sources – more than likely network or disk IO.
Not just is this really slow-moving, it’s additionally inefficient. The crawling equipment is resting there lazily for those 2-3 secs; waiting on the network to return prior to it could truly do anything or beginning refining the following demand. That’s a great deal of dead time as well as thrown away sources.
In a straightforward web scraping program from an experienced web data scraping company, you make demands in a loophole – together. You’re looking at making 20-30 demands a min if a website takes 2-3 secs to react. At this price, your spider would certainly need to compete a month, continuous prior to you made your millionth demand.
You could additionally consider methods to scale a solitary crawl throughout numerous loops, to make sure that you could also begin to press previous single-machine restrictions.
Preventing Crawler Discovery
You need to have a couple of techniques up your sleeve to earn certain that specific HTTP demands – in addition to the bigger pattern of demands as a whole – do not seem to originate from one systematized robot.
Any type of website that has a beneficial interest in securing its information will normally have some standard anti-scraping procedures in position. Amazon is absolutely no exemption.
The Spider needed to be Resistant
The spider should have the ability to run efficiently, also when confronted with usual concerns like network mistakes or unanticipated actions.
You likewise should have the ability to proceed the crawl as well as stop briefly, upgrading code along the road, without returning to “fresh start”. This permits you to upgrade parsing or crawling reasoning to repair little bugs, without should scrape every little thing you performed in the previous couple of hrs.
Squandering around lots of hrs striking the exact same links repeatedly can have a long-term adverse impact on the scraping process due to the updates taking care of tiny bugs impacting just a few web pages.













What Will We Do Next?
- Our representative will contact you within 24 hours.
- We will collect all the necessary requirements from you.
- The team of analysts and developers will prepare estimation.
- We keep confidentiality with all our clients by signing NDA.



