Best Practices for Advanced Python Web Scraping
Our achievements in the field of business digital transformation.





Data is considered vital in this modern world of digitalization. Whether you’re analyzing data for business insights, performing research, or building apps, knowing how to pull relevant information from the web properly is vital. Python, with its huge selection of libraries, is an excellent choice for web scraping activities due to its simplicity of use, versatility, and strong capabilities. However, as you progress in web scraping, you will find new obstacles and complications that necessitate sophisticated methodologies and best practices.
We’ll review advanced Python web scraping techniques and recommended practices to help you traverse the complexities of web scraping like a pro. From handling dynamic material to bypassing anti-scraping methods, we’ll teach you all you need to know to become a web scraping expert.
What is Web Scraping?
Web scraping involves extracting data from various websites and online sources. This can be done manually, which can be repetitive and time-consuming. That’s why there are many libraries and tools available to automate the process. Advanced Web Scraping doesn’t rely on a web browser to load pages; instead, it uses custom-written scripts to parse the raw responses from the server directly.
Automated web scraping increases flexibility and control over the scraping process by using self-written programs to parse raw server replies. Developers can customize the scripts to handle various website structures and data formats, ensuring operations with various sources.
Moreover, advanced web scraping projects using automated tools can be scheduled to run at given or preset times or intervals, ensuring regular data updates without constantly checking out. This feature is very important for tasks that require up-to-date information, such as tracking price changes, news updates, or social media trends.
Advanced Web Scraping Tools and Libraries
There are several advanced web scraping Python solutions available. We will use several common alternatives and explain when to use them. For quickly scraping simple websites using web scraping best practices, we discovered that combining Python Requests (for handling sessions and performing HTTP requests) with BeautifulSoup (to study the response and traverse around it to scrape data) makes an ideal combination.
Scrapy
Scrapy has proven tremendously effective for large-scale Python web scraping applications. Where we need to collect and handle a large amount of data while also dealing with non-JS-related issues using web scraping advanced tools.
Scrapy is a framework that separates several difficulties to scrape effectively (memory use, concurrent requests, etc.) and allows you to plug in a set of middleware (for redirection, sessions, cookies, caching, etc.) to deal with many difficulties. Scrapy also includes a shell, which may let you quickly prototype and authenticate your data extraction method (responses, selectors, etc.). The framework is flexible, mature, and has a strong support community.
Selenium
Selenium is often recommended for big JavaScript web pages (or those that appear overly refined). Though advanced web scraping projects using Selenium are less efficient than Beautiful Soup or Scrapy, they always produce fitting data.
How Does Web Scraping Perform?
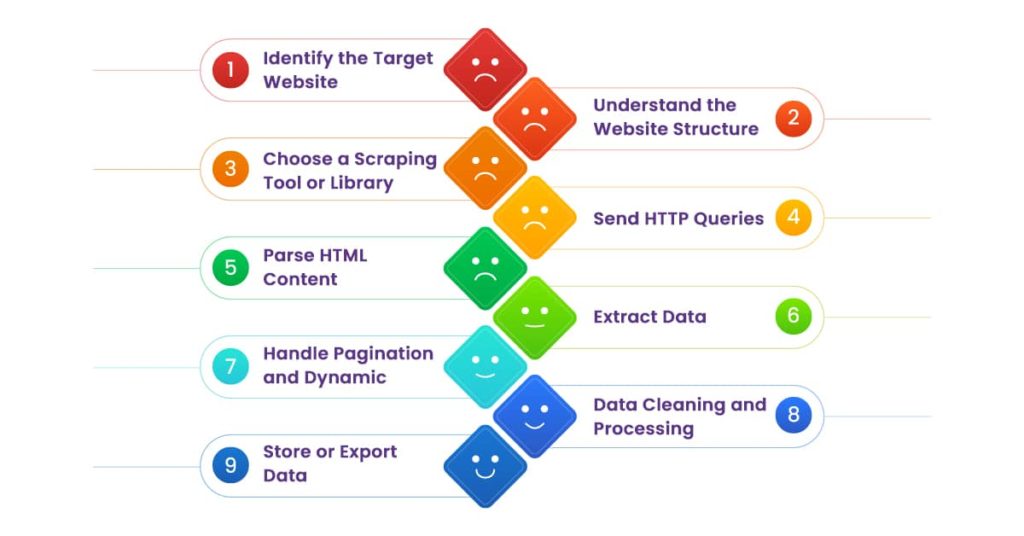
Web scraping is the process of extracting data from websites. Here’s an advanced overview of the typical steps involved in web scraping.
1. Identify the Target Website:
Determine the website from which you want to scrape data. This may be a news website, an e-commerce platform, a social media site, or any other website that provides the information you want.
2. Understand the Website Structure:
Examine the website’s structure to determine how info is arranged and displayed. Determine which HTML components (such as tags, classes, and IDs) contain the important information you wish to retrieve.
3. Choose a Scraping Tool or Library:
Choose a web scraping tool or library that is appropriate for your programming language preference, the complexity of the scraping operation, and the available capabilities. BeautifulSoup, which parses HTML; Scrapy, which performs more advanced scraping tasks; and Requests, which makes HTTP requests, are examples of popular libraries.
4. Send HTTP Queries:
Using the specified tool or library, send HTTP queries to the website’s server. This usually entails sending a GET request to the URL of the webpage you wish to scrape. The server responds with the webpage’s HTML content.
5. Parse HTML Content:
Once you have the HTML content, use the scraping library to retrieve the required data. This entails discovering specific HTML components that contain the information you’re looking for, such as article headlines, product pricing, or user reviews.
6. Extract Data:
Retrieve the needed information from the parsed HTML text. This may include approaches such as choosing specific HTML components based on their tags, classes, or IDs and then extracting text or attribute data from them.
7. Handle Pagination and Dynamic Material:
If the website shows data over several pages or loads dynamic material (e.g., via JavaScript), provide techniques for navigating between the pages or handling dynamic content. This might include imitating user activities such as clicking on pagination links or scrolling down the page to initiate content loading.
8. Data Cleaning and Processing:
Advanced scraping requires cleaning and processing the extracted data as necessary to make it worthwhile for your objectives. This may include eliminating HTML elements, stripping whitespace, changing data kinds, or dealing with missing values.
9. Store or Export Data:
Save the extracted data in an appropriate format for later analysis or usage. Standard formats are CSV (Comma-Separated Values), JSON (JavaScript Object Notation), and data stored directly in a database.
Key Considerations:
Handle failures and Exceptions:
Advanced Web Scraping Python creates error-handling techniques to cope with potential scraping difficulties such as network failures, timeouts, or changes in website structure. This ensures that your scraping script may gracefully recover from failures and continue to run.
Respect Website Policies and Terms of Service:
Ensure that your advanced scraping operations are in accordance with the website’s terms of service and any applicable legal requirements. Respect the website’s robots.txt file, which contains guidelines for web crawlers and scrapers, and avoid scraping sites that are explicitly prohibited.
Complexities With Web Scraping
An advanced web scraper is a helpful technique for obtaining data from web pages, has its own set of difficulties and obstacles. Here are some of the major complications related to web scraping.
Handling Authentication:
For authentication, because we’ll need to keep cookies and persist our login, it’s best to construct a session that handles everything. To find hidden fields, we may manually log in and check the payload transferred to the server using the browser’s network tools.
We can also use browser tools to check what headers are being provided to the server so that we can reproduce that behavior in code (for example, if authentication is based on headers such as Authorization and Authentication). Suppose the site employs basic cookie-based authentication (which is really unusual these days). In that case, we can copy the cookie contents and paste them into your scraper’s code (again, we can use built-in browser features) utilizing web scraping advanced tools and techniques.
Handling Asynchronous Loading
1. Detecting Asynchronous Loading
We can detect asynchronous loading in the visual inspection process by inspecting the page’s source (the “View Source” option in the browser on right-click) and then searching for the desired content. If the text does not appear in the source but is visible in the browser, it is most likely displayed with JavaScript. Further investigation may be performed with the browser’s network tool to see if the site is making any XHR requests.
2. Getting Around Asynchronous Loading
Step 1. A web driver is a browser emulation with a scriptable interface. It is capable of performing browser functions such as rendering JavaScript, managing cookies and sessions, and so on. Selenium Web Driver is a web automation framework developed to test website UI/UX, but it has also gained popularity as a tool for scraping dynamically generated web pages over time.
Step 2. Inspecting AJAX calls
This strategy is based on the concept that “if it’s being displayed in the browser, it has to come from somewhere.” We may use browser developer tools to analyze AJAX calls and determine which queries are responsible for retrieving the desired data. We may need
to use the X-Requested-With header to simulate AJAX queries in your script.
Step 3. Tackling endless scrolling
We can solve endless scrolling by inserting javascript logic into Selenium (see this SO discussion). Also, the endless scroll typically includes additional AJAX requests to the server, which we can analyze with browser tools and imitate in our scraping software.
Step 4. Handling redirections and captchas
Modern libraries, such as requests, already handle HTTP redirects by following them (keeping track of the history) and returning the final page. Scrapy also has a redirect middleware to manage redirection. Redirects aren’t too bad as long as we end up on the correct website. However, the situation becomes more complicated if we are referred to as a captcha. Very simple text-based captchas can be solved with OCR. Text-based captchas are becoming increasingly difficult to implement as improved OCR algorithms (based on Deep Learning, such as this one) become available, making it more difficult to produce pictures that can beat computers but not people.
Also, when we don’t want to deal with the hassle of solving captchas, there are several services that offer APIs for it, such as Death by Captcha, Anti gate, and Anti Captcha. Some of these firms use genuine people who are paid to solve captchas for you. You may be able to evade captchas to some extent by employing proxies and IP rotation.
Handling Iframe Tags and Unstructured Responses
To retrieve data from iframe tags, simply request the relevant URL. The external page must be visited, the iframe found, and a second HTTP request performed to the iframe’s src attribute. Furthermore, the only practical answer for unstructured HTML and URL patterns is to invent workarounds (forming complex XPath searches, using regexes, and so on).
Strategies for Advanced Web Scraping with Python
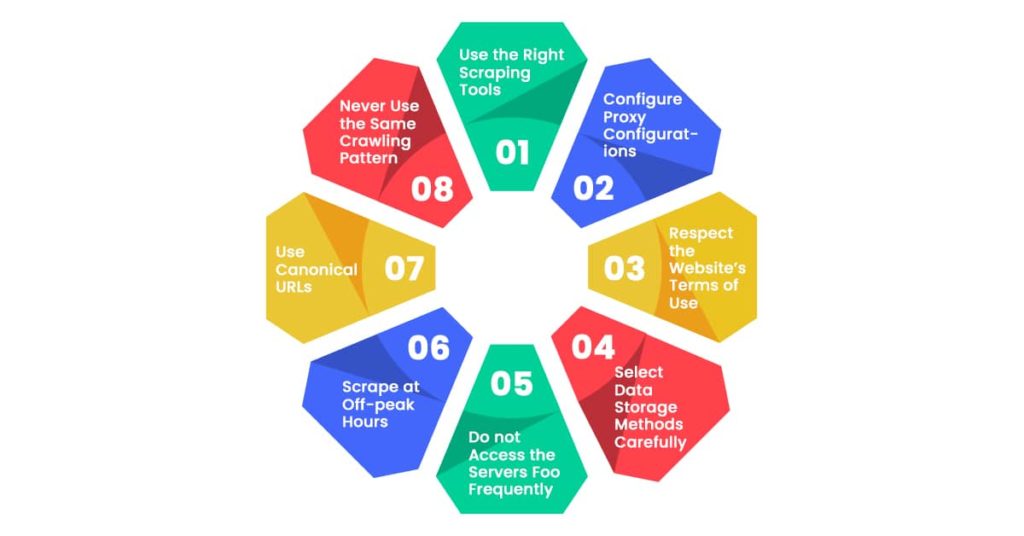
Advanced web scraping with Python involves employing various strategies to overcome challenges such as dynamic content, anti-scraping measures, and large-scale data extraction. Here are some strategies to consider:
1. Use the Right Scraping Tools
The most popular Python web scraping libraries are Beautiful Soup, Scrapy, and Selenium. To submit HTTP requests, add the Requests library to your project using ‘import requests.’ Choosing the best library for your needs is one of the most critical tasks.
On the other hand, leveraging a popular advanced web scraper and web scraping API has a significant benefit in web scraping procedures. Developers can access data via API queries and analyze it using Python packages and web scraping best practices.
2. Configure Proxy Configurations:
If you are not utilizing a web scraping API, it is critical to specify proxy settings. You should also enable automatic IP rotation in your proxy settings to ensure that the destination website does not blacklist the IP address. This allows you to develop seamless web scraping procedures.
3. Respect the Website’s Terms of Use:
Before beginning advanced web scraping projects, it is vital to review the terms of service of the website and ensure that web scraping is appropriate. Some websites may restrict or only allow web scraping under specified conditions. Because of this, it is suggested that you thoroughly study the website’s robots.txt file and terms of service before utilizing your web scraper.
4. Select Data Storage Methods Carefully:
Web scraping may yield vast amounts of data. It is critical that large datasets are correctly stored. The Python programming language is readily integrated with RDMS and NOSQL databases.
5. Do not Access the Servers Foo Frequently:
Some websites will provide a frequency interval for crawlers. We should utilize it prudently because not every website has been tested for big loads. If you hit at regular intervals, it generates a lot of load on the server, which might cause it to crash or not process other requests. This significantly influences the user experience since they are more important than the bots. As a result, we should send requests based on the period indicated in robots.txt or with a 10-second delay. This also helps you avoid getting banned by the target website.
6. Scrape at Off-peak Hours:
Off-peak hours are ideal for bots/crawlers because the website’s traffic is significantly lower. These hours can be recognized by the geolocation of the site’s traffic source. This also helps to increase the crawling rate and avoid the additional burden caused by spider queries. Thus, it is best to plan the crawlers to operate during off-peak hours.
7. Use Canonical URLs:
When at 3i Data Scraping employs web scraping best practices, we frequently scrape duplicate URLs and, hence, duplicate data, which is the last thing we want to do. Numerous URLs with the same data may be generated from a single website. In this case, duplicate URLs will have a canonical URL that redirects to the parent or original URL. We ensure that we do not scrape duplicate material. Scrapy, for example, handles duplicate URLs by default.
8. Never Use the Same Crawling Pattern:
As you are aware, many websites utilize anti-scraping technology, making it easier for them to identify your spider if it crawls in the same way. As humans, we typically would not follow a pattern on a certain website. To ensure that your spiders function smoothly, we can include behaviors such as mouse movements, clicking a random link, and so on that give the idea that your spider is human.
Conclusion
Mastering advanced Python web scraping necessitates a mix of technical knowledge, inventiveness, and following web scraping best practices. Understanding the complexities of managing dynamic content, authentication, pagination, error handling, and ethical issues allows you to create strong and fast scraping programs capable of retrieving important data from the web. 3i Data Scraping always follows website policies, avoids aggressive scraping strategies, and aims for ethical scraping practices to create a great scraping experience for both you and the websites you scrape.
Whether you’re scraping data for research, corporate intelligence, or personal projects, these approaches can help you overcome obstacles and get insights from the wide expanse of the Internet.













What Will We Do Next?
- Our representative will contact you within 24 hours.
- We will collect all the necessary requirements from you.
- The team of analysts and developers will prepare estimation.
- We keep confidentiality with all our clients by signing NDA.



