How BeautifulSoup is Used to Web Scrape Movie Database?
Our achievements in the field of business digital transformation.




You want to use machine learning to forecast what will be the next popular film. You try and attempt to locate clean data to develop a machine learning model, but you can’t seem to find any. So, you decide to create your data. However, you are afraid to gather your information because you may not be familiar with HTML or web scraping.
Beautiful Soup is a Python web scraping module that makes it simple to scrape HTML and XML files. The documentary on the library can be found here: Documentation
By following this lesson, you will obtain a considerable understanding of how to produce your data if you already know how to use Python.
Steps for Web Scraping:
- Determine what data you want to extract from the website.
- Examine the page
- Beautiful Soup is a great place to start scraping.
Target
For scraping the database of Ghibli studio and look for characteristics that make a Ghibli movie better.
On the first page:
- Title
- URL: for future web scraping
- Image
- Ranks
- Ratings
Examining the page:
Right-click on the page and then click on inspect
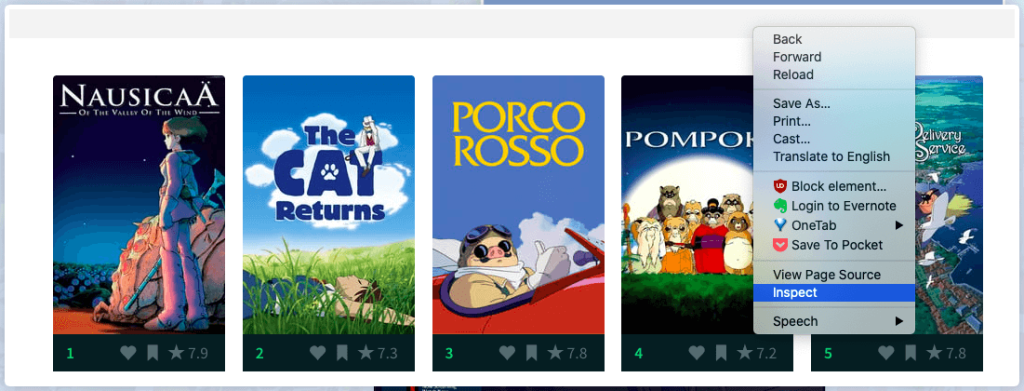
Then click on the icon to select the element on the website to inspect
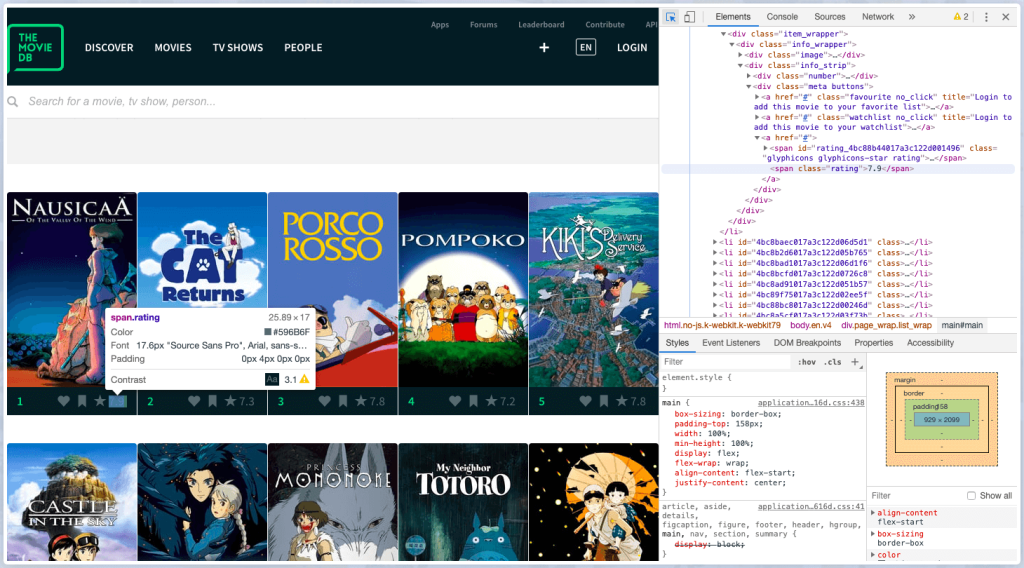
For individuals who are unfamiliar with HTML, the text can appear confusing at first. But don’t worry; after working with a few of them, you’ll quickly grasp the framework. You can then click on any information on the website that interests you after clicking on the button indicated earlier. Do you want to start by scraping the rating? Simply click on the location of the rating. The specific placement of the rating on the HTML program code will be known to you.
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
from urllib.request import urlopenhtml = urlopen('https://www.themoviedb.org/list/4309')
bsObj = BeautifulSoup(html)
bsObj.prettify()
The result is a tangled HTML document. However, keep in mind that the movie list is encased in an unordered list <ul> element with attributeid = “list page 1.” Find all to extract data (tag, attribute). Then, within the <ul> tag, get a list of all <li> tags.
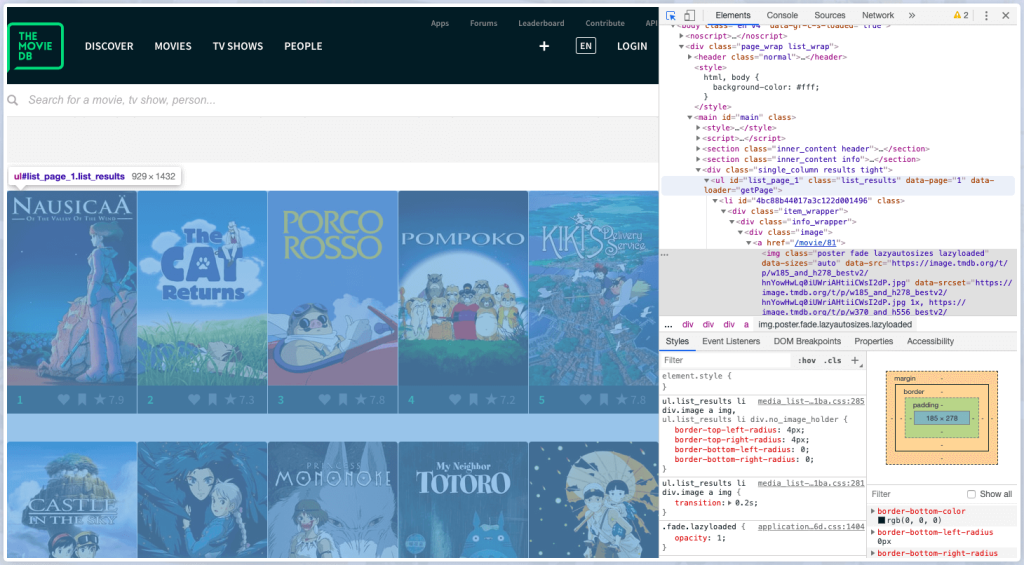
movies = bsObj.find('ul', id = "list_page_1")
movies = movies.find_all('li')
len(movies)
for movie in movies:
print(movie, len(movie), "\n\n")
The function find all() creates a set of objects that have the tag provided in the brackets. We understand the duration of the film item is 3 depending on length of each item in the list. As a result, the items having a length greater than 0 would provide us with information on the movies.
movies = [movie for movie in movies if len(movie) > 0]
The data we really want scrape on the first page is title, URL, image, rank, and rating.
Each film is wrapped in a unique tag that follows the same format. So, to see if we get what we want, we may start by extracting information from the first movie. Then, using identical scripts, loop over all of the videos to retrieve all of the data we care about.
Begin on the first page. The image’s URL and title are enclosed within the img tag, as we can see. li is our current tag. We’re looking for a means to acquire entry to the img tag and its characteristics.
movie_1 = movies[0]
movie_1.img.attrs
Let’s have a look at this in more detail. The img tag that is wrapped inside the current tag is returned by.img. The img tag’s attribute can be accessed using attrs.
{'class': ['poster', 'lazyload', 'fade'],
'data-sizes': 'auto',
'data-src': 'https://image.tmdb.org/t/p/w185_and_h278_bestv2/hnYowHwLq0iUWriAHtiiCWsI2dP.jpg',
'data-srcset': 'https://image.tmdb.org/t/p/w185_and_h278_bestv2/hnYowHwLq0iUWriAHtiiCWsI2dP.jpg 1x, https://image.tmdb.org/t/p/w370_and_h556_bestv2/hnYowHwLq0iUWriAHtiiCWsI2dP.jpg 2x',
'alt': 'Nausicaä of the Valley of the Wind'}
Searching for the Title
movie_1.img.attrs['alt']
Result
'Nausicaä of the Valley of the Wind'
Check if the link to the movie’s image is working, find the URL and use Image to see the image.
from IPython.display import Image
image_url = movie_1.find('img').attrs['data-src']
Image(url= image_url)

Extracting URL by accessing to tag and then to its attribute href.
a = movie_1.a.attrs
for value in a.values():
url = value
print(url)
Outcome
/movie/81
https://www.themoviedb.org/movie/81 is the URL for the film “.
full_url = "https://www.themoviedb.org" + url
Access the div tag with class=’number’ to find the rank. The span tag is then accessed. The text inside the tag is returned by text.
int(movie_1.find('div', {'class':'number'}).span.text)
Perform the previous steps to search for the ratings:
float(movie_1.find_all('span',{'class':'rating'})[1].text)
Loop through all the movies using the script:
html = urlopen('https://www.themoviedb.org/list/4309')
bsObj = BeautifulSoup(html)
#Create 4 lists that contains all the url, movie's name, rank, and rating
urls = []
names = []
ranks = []
ratings = []
images = []
for movie in movies:
for value in movie.a.attrs.values():
url = value
urls.append("https://www.themoviedb.org" +url)
names.append(movie.img.attrs['alt'])
ranks.append(int(movie.find('div', {'class':'number'}).span.text))
ratings.append(float(movie.find_all('span',{'class':'rating'})[1].text))
images.append(movie.find('img').attrs['data-src'])
Search the Next Tag and Scrape Various Pages
In the movie list, select one of the films. Extract data about the film from the URL you found earlier, such as the summary, director, language, runtime, budget, revenue, and genre.
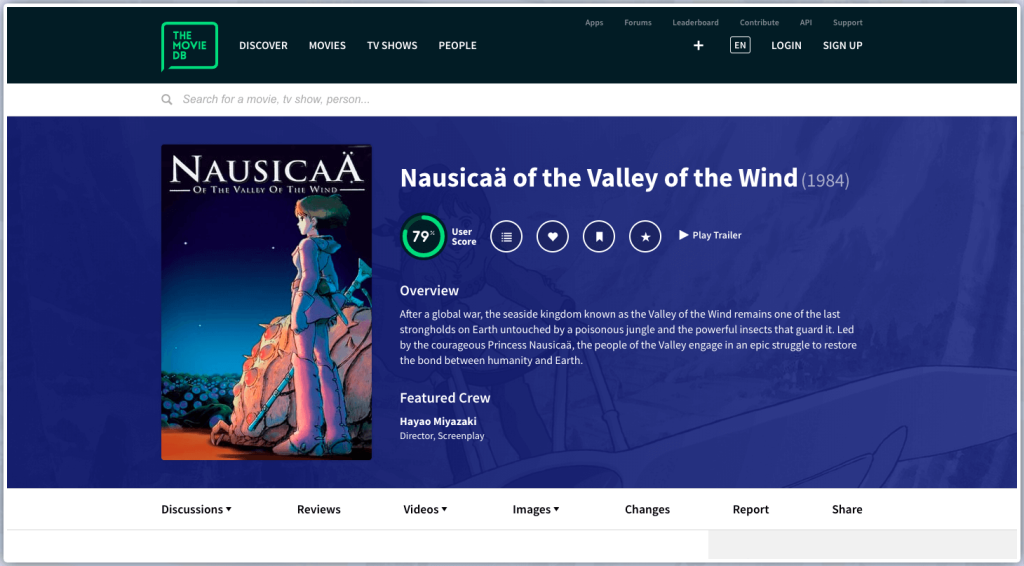
If you want to get to the <p> tag that contains the information you’re interested in but the tag doesn’t have a specific characteristic to call, you can use. Find_next_ siblings() to get to the p tag by using the same hierarchy as the ul tag above.
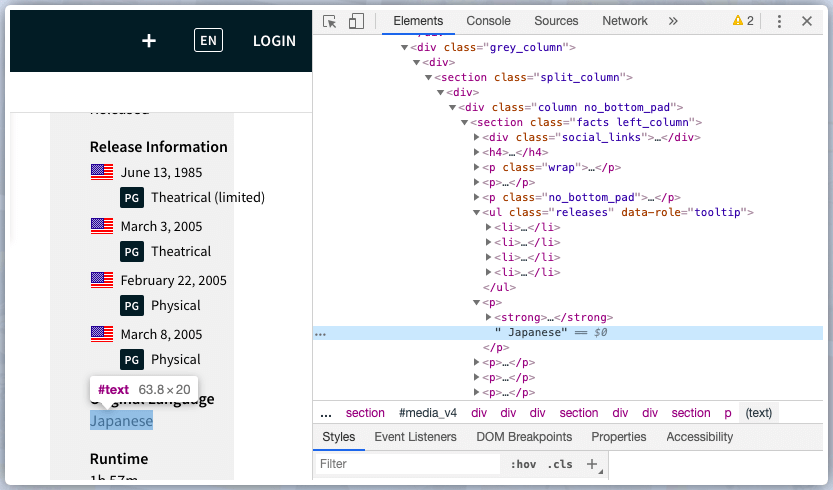
Now we are ready to scrape various pages at same time
url = urlopen("https://www.themoviedb.org/movie/81")
soup = BeautifulSoup(url)
#find summary
soup.find('div', {'class':'overview'}).p.get_text()
#find director
soup.find('li', {'class':'profile'}).a.get_text()
#Find language, runtime, budget, revenue, and genre
inf = soup.find('ul', {'class':'releases'}).find_next_siblings()
language = inf[0].text
runtime = inf[1].text
budget = inf[2].text
rev = inf[3].text
#Find Genre
section = soup.find('section',{'class':'genres right_column'})
[li.text for li in section.find_all('li')]
# Scrap every page
summaries = []
languages = []
runtimes = []
budgets = []
revenues = []
genres = []
directors = []
for url in urls:
soup = BeautifulSoup(urlopen(url))
summaries.append(soup.find('div', {'class':'overview'}).p.get_text())
inf = soup.find('ul', {'class':'releases'}).find_next_siblings()
languages.append(inf[0].text)
runtimes.append(inf[1].text)
budgets.append(inf[2].text)
revenues.append(inf[3].text)
directors.append(soup.find('li', {'class':'profile'}).a.get_text())
section = soup.find('section',{'class':'genres right_column'})
genres.append([li.text for li in section.find_all('li')])
Put Data into DataFrame
import pandas as pd
ghibli = pd.DataFrame(list(zip(names, ranks, ratings, languages, runtimes, budgets, revenues, genres, summaries)),
columns=['name','rank','rating','language','runtime', 'budget','revenue','genre','summary'])
ghibli.head(10)
Final Result
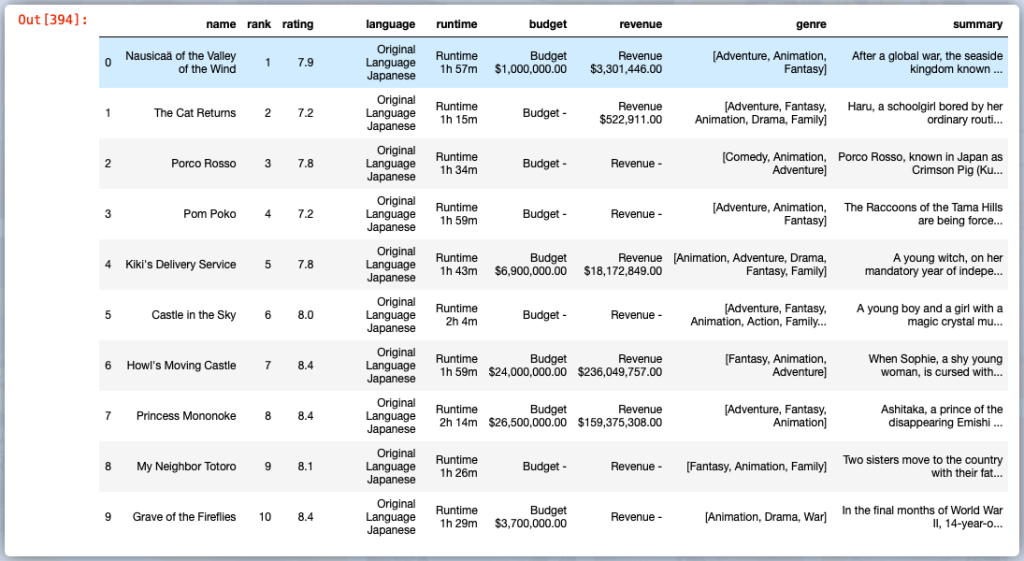
Use this method to extract the information, that you want to. If you’re not sure where to begin, try practicing with The Movie Database on an area that interests you. You’d be astonished at how simple scraping is. Plus, watching what you can scrape with just a few lines of code will be entertaining.
Contact 3i Data Scraping for any queries,
Request for a quote!!













What Will We Do Next?
- Our representative will contact you within 24 hours.
- We will collect all the necessary requirements from you.
- The team of analysts and developers will prepare estimation.
- We keep confidentiality with all our clients by signing NDA.



