How Can We Use Python and BeautifulSoup to Scrape Groupon Data?
We will have a look at a simple way to scrape Groupon deal information using Python and BeautifulSoup. The goal is to get you started on receiving solutions to real-life issues while making them as general as possible so that you can get familiar with them and get concrete results as quickly as feasible.
Our achievements in the field of business digital transformation.





Contents
Today, we’ll look at a simple and effective way to scrape Groupon deal data using Python and BeautifulSoup.
The main objective of this post is to get you started on real-world solving problems while making them as easy as possible so that you can become familiar with them and receive real applications as quickly as feasible.
So, the only thing we need to assure is to install Python 3. If not installed, then you can initially install Python 3 and then proceed.
Afterwards you can install BeautifulSoup with:
Install BeautifulSoup
pip3 install beautifulsoup4
To fetch data, split it down to XML, and apply CSS selectors, we’ll also require the libraries’ requirements, soupsieve, and LXML. Install them by following these steps:
pip3 install requests soupsieve lxml
After installation, you need to open an editor and type:
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests
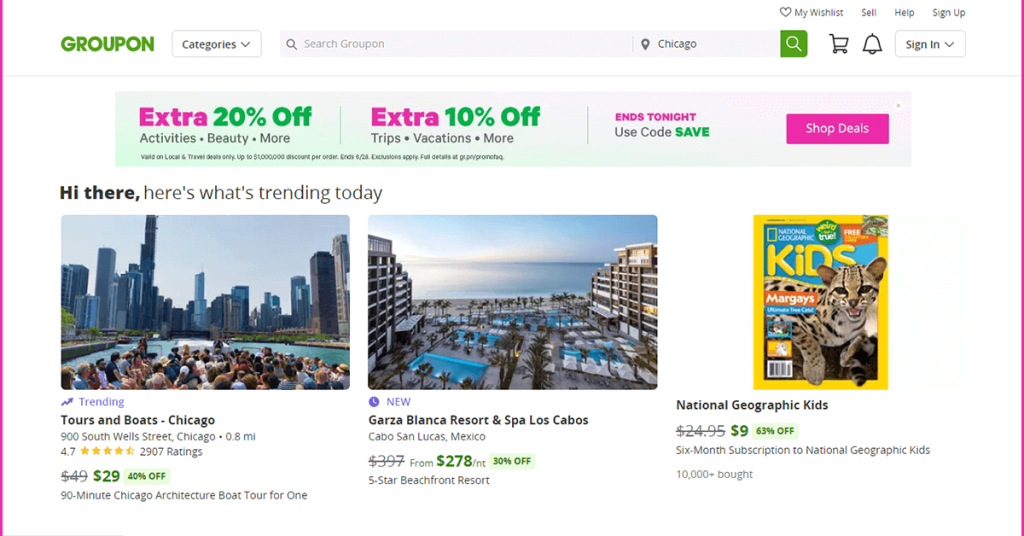
Now, let us visit Groupon page and check the information we get. This is how it will look.
Code
We would also require LXML, library’s requests, as well as soupsieve for fetching data, break that down to the XML, as well as utilize CSS selectors. Then install them with:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.11 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9',
'Accept-Encoding': 'identity'
}
#'Accept-Encoding': 'identity'
url = 'https://www.groupon.com/browse/greater-toronto-area'
response=requests.get(url,headers=headers) Save this file as scrapeGroupon.py.
If you execute the code:
python3 scrapeGroupon.py
You will find the entire HTML page.
Now let’s utilize CSS selectors to get through to the information we’re looking for. To do so, return to Chrome and launch the inspect tool. Now, we must complete all of the articles. All of the different product data are held together by the div with the class ‘cui-content.’
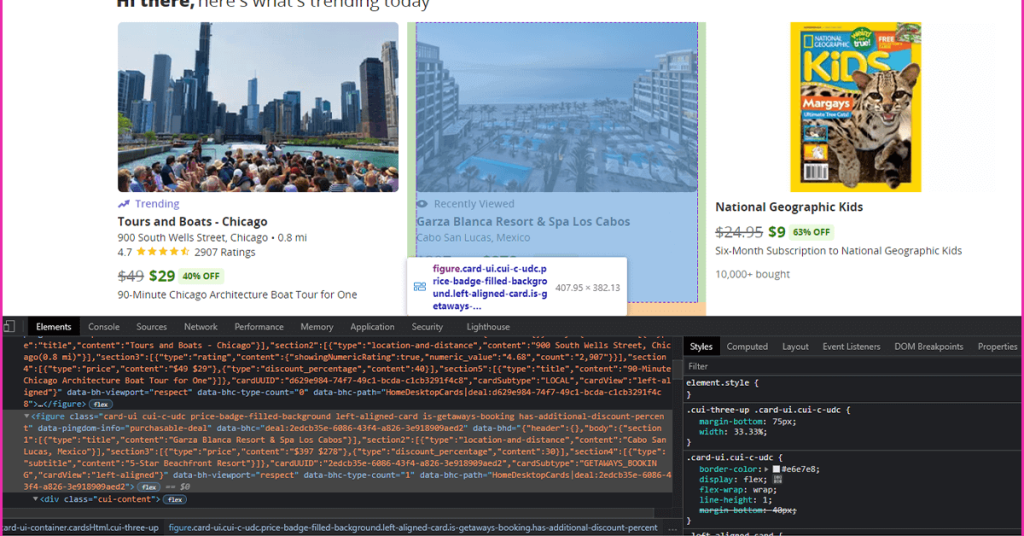
The product title is included within the cui-udc-title class, as you can see. Let’s take a look at how we can do it:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.11 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9',
'Accept-Encoding': 'identity'
}
#'Accept-Encoding': 'identity'
url = 'https://www.groupon.com/browse/greater-toronto-area'
response=requests.get(url,headers=headers)
#print(response.content)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('.cui-content'):
try:
print(item.select('.cui-udc-title')[0].get_text().strip())
print('---------------------------')
except Exception as e:
#raise e
print('')
So, when you execute:
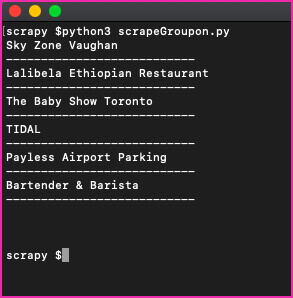
Yes, here we get the title
Now, using the same procedure, we can obtain the class names for all additional data, such as specific products, costs, and so on.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.11 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9',
'Accept-Encoding': 'identity'
}
#'Accept-Encoding': 'identity'
url = 'https://www.groupon.com/browse/greater-toronto-area'
response=requests.get(url,headers=headers)
#print(response.content)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('.cui-content'):
try:
print(item.select('.cui-udc-title')[0].get_text().strip())
print('---------------------------')
except Exception as e:
#raise e
print('') When you execute, it must print everything we require from each product you need.
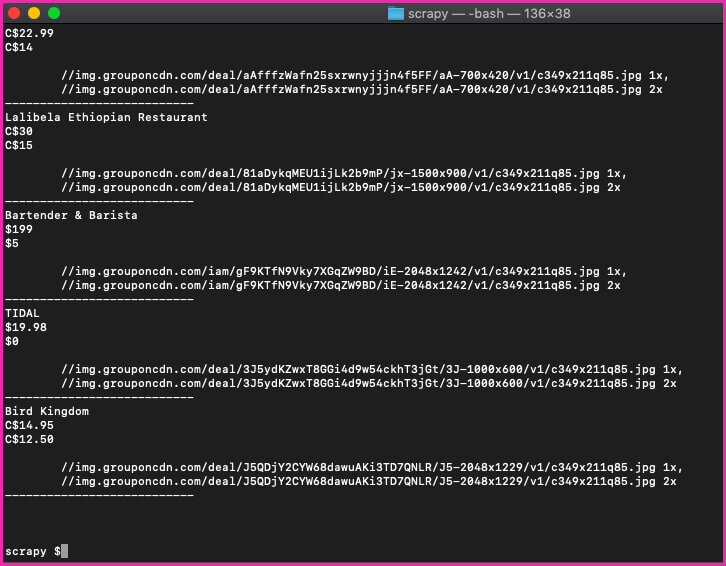
If you’d like to use this in reality and scale to hundreds of links, you’ll find that Groupon simply blocks your IP address. Using a rotating proxy service to cycle IPs is really a must in this case. You can route your calls through a pool of hundreds of residential proxies using a service like Proxies API.
If you want to increase the speed of crawling but don’t want to set up your own infrastructure, you can utilize our crawler to quickly crawl thousands of URLs from our network of crawlers.
You can ask for any queries or free quotes!!!!













What Will We Do Next?
- Our representative will contact you within 24 hours.
- We will collect all the necessary requirements from you.
- The team of analysts and developers will prepare estimation.
- We keep confidentiality with all our clients by signing NDA.



