How Scrapy and Selenium are used in Analyzing and Scraping News Articles?
Our achievements in the field of business digital transformation.





Scraping
Selenium got its start as a web testing tool. Someone, who has never done web testing previously, will find it entertaining to play with — as you will sit there watching your browser being possessed — no, programmatically commanded — to do all sorts of things while sipping coffee with both hands.
Here is the script to get started:
scrapy startproject [project name]
cd [project name]
scrapy genspider [spider name]The web driver must be located on the first level of the project folder, which is the same level as the “scrapy.cfg” file, which must be taken care of.
CNN
Without JavaScript, the search word would not even appear on CNN, and we would be presented with a blank page —
This, on the other hand, demonstrates the pleasure (and problems) of JavaScript
So, we’ll need to replicate the process of transferring search requests (simply using the “search?q=” string in the URL would serve, but the following will show a more full method of running Selenium from the home page). After that, we’ll look at pagination —

On a side note, the “Date” button will just allow you to rank by date or relevance, it will not allow you to search for a particular date range. The code for scraping CNN is below, along with an explanation in the comments.
import scrapy
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from scrapy.selector import Selector
import time
class CnnSpider(scrapy.Spider):
name = 'cnn'
allowed_domains = ['www.cnn.com']
start_urls = ['https://www.cnn.com']
# initiating selenium
def __init__(self):
# set up the driver
chrome_options = Options()
# chrome_options.add_argument("--headless") # uncomment if don't want to appreciate the sight of a possessed browser
driver = webdriver.Chrome(executable_path=str('./chromedriver'), options=chrome_options)
driver.get("https://www.cnn.com")
# begin search
search_input = driver.find_element_by_id("footer-search-bar") # find the search bar
search_input.send_keys("immigration") # type in the search term
search_btn = driver.find_element_by_xpath("(//button[contains(@class, 'Flex-sc-1')])[2]") # find the search button
search_btn.click()
# record the first page
self.html = [driver.page_source]
# start turning pages
i = 0
while i < 100: # 100 is just right to get us back to July
i += 1
time.sleep(5) # just in case the next button hasn't finished loading
next_btn = driver.find_element_by_xpath("(//div[contains(@class, 'pagination-arrow')])[2]") # click next button
next_btn.click()
self.html.append(driver.page_source) # not the best way but will do
# using scrapy's native parse to first scrape links on result pages
def parse(self, response):
for page in self.html:
resp = Selector(text=page)
results = resp.xpath("//div[@class='cnn-search__result cnn-search__result--article']/div/h3/a") # result iterator
for result in results:
title = result.xpath(".//text()").get()
if ("Video" in title) | ("coronavirus news" in title) | ("http" in title):
continue # ignore videos and search-independent news or ads
else:
link = result.xpath(".//@href").get()[13:] # cut off the domain; had better just use request in fact
yield response.follow(url=link, callback=self.parse_article, meta={"title": title})
# pass on the links to open and process actual news articles
def parse_article(self, response):
title = response.request.meta['title']
# several variations of author's locator
authors = response.xpath("//span[@class='metadata__byline__author']//text()").getall()
if len(authors) == 0:
authors = response.xpath("//p[@data-type='byline-area']//text()").getall()
if len(authors) == 0:
authors = response.xpath("//div[@class='Article__subtitle']//text()").getall()
# two variations of article body's locator
content = ' '.join(response.xpath("//section[@id='body-text']/div[@class='l-container']//text()").getall())
if content is None:
content = ' '.join(response.xpath("//div[@class='Article__content']//text()").getall())
yield {
"title": title,
"byline": ' '.join(authors), # could be multiple authors
"time": response.xpath("//p[@class='update-time']/text()").get(),
"content": content
}FOX News
Scraping Fox News would be comparable, just like we’re dealing with the Show More button instead of standard pagination —
Only the significant deviations from the CNN spider are discussed this time.
import scrapy
from scrapy.selector import Selector
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import time
class FoxnewsSpider(scrapy.Spider):
name = 'foxnews'
allowed_domains = ['www.foxnews.com']
start_urls = ['https://www.foxnews.com']
def __init__(self):
chrome_options = Options()
#chrome_options.add_argument("--headless")
driver = webdriver.Chrome(executable_path=str('./chromedriver'), options=chrome_options)
driver.get("https://www.foxnews.com/category/us/immigration")
wait = WebDriverWait(driver, 10)
# first, click 'Show More' many times
i = 0
while i < 80:
try:
time.sleep(1)
element = wait.until(EC.visibility_of_element_located(
(By.XPATH, "(//div[@class='button load-more js-load-more'])[1]/a")))
element.click()
i += 1
except TimeoutException:
break
# then, copy down all that's now shown on the page
self.html = driver.page_source
def parse(self, response):
resp = Selector(text=self.html)
results = resp.xpath("//article[@class='article']//h4[@class='title']/a")
for result in results:
title = result.xpath(".//text()").get()
eyebrow = result.xpath(".//span[@class='eyebrow']/a/text()").get() # scraped only for filtering
link = result.xpath(".//@href").get()
if eyebrow == 'VIDEO':
continue # filter out videos
else:
yield response.follow(url=link, callback=self.parse_article, meta={"title": title})
def parse_article(self, response):
title = response.request.meta['title']
authors = response.xpath("(//div[@class='author-byline']//span/a)[1]/text()").getall()
if len(authors) == 0:
authors = [i for i in response.xpath("//div[@class='author-byline opinion']//span/a/text()").getall() if 'Fox News' not in i]
content = ' '.join(response.xpath("//div[@class='article-body']//text()").getall())
yield {
"title": title,
"byline": ' '.join(authors),
"time": response.xpath("//div[@class='article-date']/time/text()").get(),
"content": content
}To execute these spiders, simply type the following into Terminal:
scrapy crawl [spider name] [-o fileName.csv/.json/.xml]
# Saving the output to a file is optional
# only these three file types are allowed by ScrapyWant To Get News Articles Data?
Analyzing
Scrapy does not process data in order, thus the data we collected would be in a bizarre sequence. To expedite the procedure, multiple requests are sent at the same time.
For this section, we’ll need the following packages:
# for standard data wrangling
import pandas as pd
import numpy as np# for plotting
import matplotlib.pyplot as plt# for pattern matching during cleaning
import re# for frequency counts
from collections import Counter# for bigrams, conditional frequency distribution and beyond
import nltk# for word cloud
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
from PIL import Image# for (one way of) keyword extraction
from sklearn import feature_extraction
from nltk.stem.snowball import SnowballStemmer
from sklearn.feature_extraction.text import TfidfVectorizerHere is a demo of CNN and the Fox News data:


There seem to be a few typical cleaning procedures to consider, which will ultimately depend on our goals. If we only want to look at the content, for example, we can disregard the chaos in other columns entirely.
1. Discard articles in unusual formats, such as slideshows (which result in NAs).
df = df.dropna(subset=['column to consider']).reset_index(drop=True)2. Format Dates
# for CNN
df['date'] = df['time'].apply(lambda x: x.split('ET,')[1][4:].strip())
df.date = pd.to_datetime(df.date, format = '%B %d, %Y')# for Fox News
for _, row in df.iterrows():
if 'hour' in row['time']:
row['time'] = ('March 24, 2021')
elif 'day' in row['time']:
day_offset = int(row['time'].split()[0])
row['time'] = 'March {}, 2021'.format(24 - day_offset)
elif ('March' in row['time']) or ('February' in row['time']) or ('January' in row['time']):
row['time'] += ', 2021'
else:
row['time'] += ', 2020'
df = df.rename(columns = {'time':'date'})
df.date = df.date.apply(lambda x: x.strip())
df.date = pd.to_datetime(fn.date, format = '%B %d, %Y')In addition, we also included a new month-year column for future aggregate reports. It also aids in the removal of unneeded items released in July (previously scraped with rough page counts).
df['month_year'] = pd.to_datetime(df['date']).dt.to_period('M')
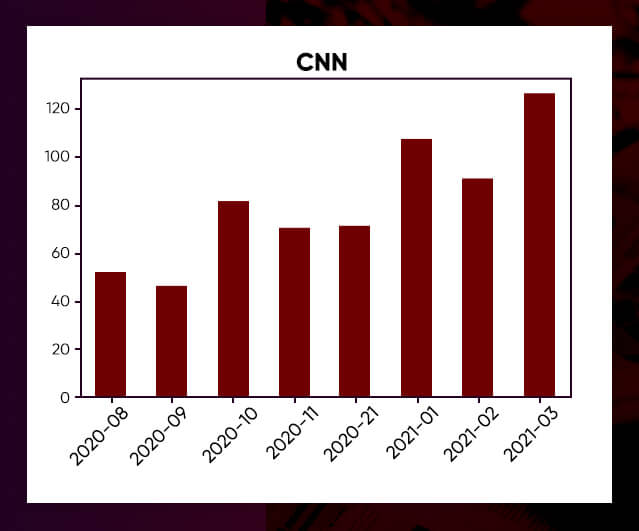
df_cleaned = df[df['month_year']!=pd.Period('2020-07', 'M')].copy()We now have 644 CNN stories and 738 Fox News articles after cutting. Both media organizations appear to be increasing the number of immigration-related pieces published each month, with Fox showing a noticeable surge in interest in March.
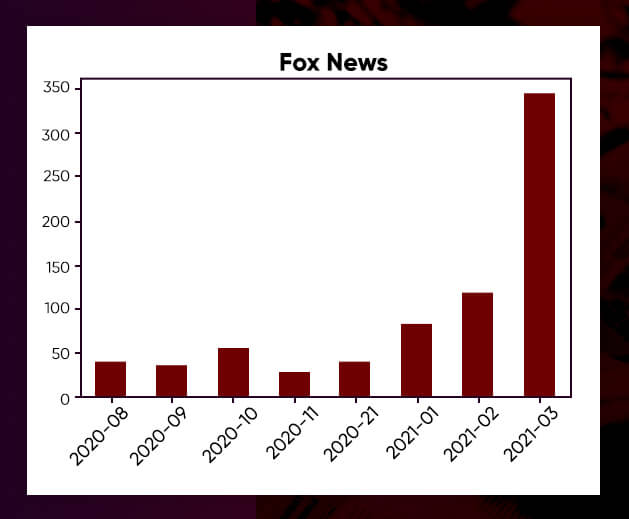
3. Clean Articles
Because the scraping stage had indiscriminately included all the extraneous stuff, such as ad banners, media sources, and markups like “width” or “video closed,” we could do a far finer job cleaning the body of a post. Some of those, on the other hand, would scarcely compromise our textual analysis.
We could perform a far better job cleaning the content of a post because the scraping stage has randomly included those unnecessary stuff, such as ad banners, media sources, and markups like “width” or “video closed.” But at the other side, several of these would hardly impair our text analysis.
df['content'] = df['content'].apply(lambda x: x.lower())
cnn.content = cnn.content.apply(lambda x: re.sub(r'use\sstrict.*?env=prod"}', '', x))World Cloud
Here we will initiate, with headlines to make sense of the variation between two publications.
stopwords = nltk.corpus.stopwords.words('english')
stopwords += ['the', 'says', 'say', 'a'] # add custom stopwords
stopwords_tokenized = nltk.word_tokenize(' '.join(stopwords))
def process(text):
tokens = []
for sentence in nltk.sent_tokenize(text):
for word in nltk.word_tokenize(sentence):
token = word.lower().replace("'", "") # put words like 'she and she as one
if ('covid-19' in token) or ('coronavirus' in token): # publications use different terms for covid
tokens.append('covid') # normalize all the mentions since this is a crucial topic as of now
else:
tokens.append(token)
tokens_filtered = [t for t in tokens
if re.search('[a-zA-Z]', t) and t not in stopwords_tokenized]
return tokens_filtered
def gen_wc(bag, name=''):
tokens = process(bag)
plt.figure(figsize=(20,10), dpi=800)
wc = WordCloud(background_color="white",width=1000, height=500) #other options like max_font_size=, max_words=
wordcloud = wc.generate_from_text(' '.join(tokens))
plt.imshow(wordcloud, interpolation="nearest", aspect="equal")
plt.axis("off")
plt.title('Words in Headlines-{}'.format(name))
plt.savefig('headline_wc_{}'.format(name)+'.png', figsize=(20,10), dpi=800)
plt.show()
# generate word cloud for each month
for time in df['month_year'].unique():
df_subset = df[df['month_year']==time].copy()
bag = df_subset['title'].str.cat(sep = ' ')
gen_wc(bag, name=time)Here is the keyword in headline for CNN across every month.
All of the words are capitalised, so “us” means “US” and “ice” means “ICE” (Immigration and Customs Enforcement), and so on.
FOX News:
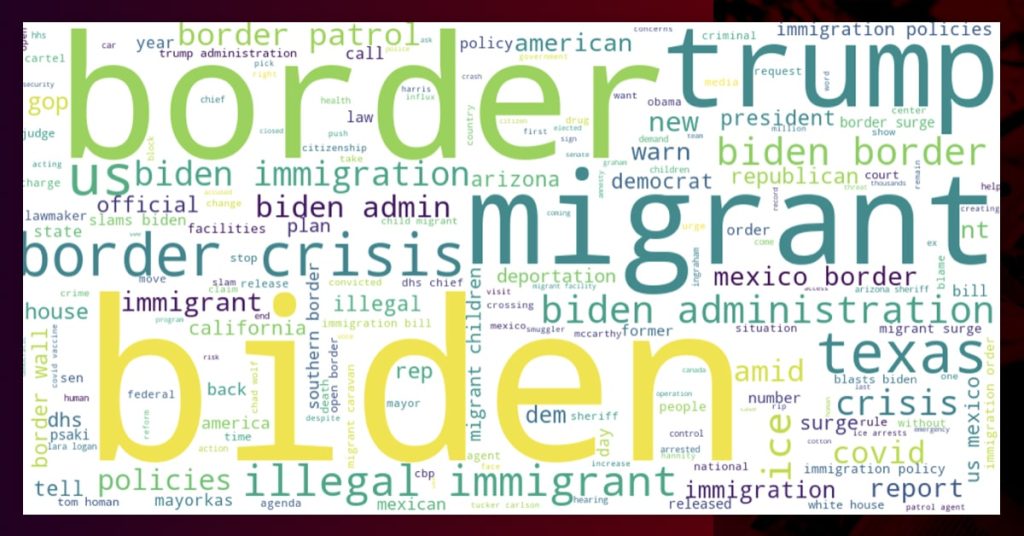
Bigrams:
Another thing we will look at is Bigrams.
out = []
for title in list(df['title']):
out.append(nltk.word_tokenize(title))bi = []
for title_words in out:
bi += nltk.bigrams(title_words)Counter(bi).most_common()There are a few unusual bigrams among the anticipated popular ones, such as “Biden administration” and “Trump administration.”
With the bigram list, we could conduct a conditional relative frequency search for certain keyword pairings. For instance ,

cfd = nltk.ConditionalFreqDist(bi)cfd['Covid']
# CNN: FreqDist({'relief': 8, ',': 6, 'law': 1})
cfd['coronavirus']
# Fox News: FreqDist({'pandemic': 4, 'death': 2, 'vaccine': 1, 'relief': 1, 'records': 1, 'travel': 1, 'is': 1, 'rules': 1, 'canceled': 1, ',': 1, ...})cfd['border']
# CNN: FreqDist({'wall': 7, 'crisis': 3, 'is': 3, '.': 2, ',': 2, 'alone': 2, 'surge': 1, 'closed': 1, 'problem': 1, 'encounters': 1, ...})
# Fox News: FreqDist({'crisis': 50, 'wall': 19, ',': 14, 'surge': 13, ':': 8, 'as': 7, 'policy': 7, 'crossings': 6, "'crisis": 5, 'situation': 5, ...})Changing Over Time
It would be interesting to see how word frequency changed over the course of eight months, and hence created a new dataset with monthly word counts:
bag = df['title'].str.cat(sep = ' ')
tokens = process(bag)
word_df = pd.DataFrame.from_dict(dict(Counter(tokens)), orient='index', columns=['overall'])# create a custom merge
def merge(original_df, frames):
out = original_df
for df in frames:
out = out.merge(df, how='left', left_index=True, right_index=True)
return outframes = []
for time in df['month_year'].unique()[::-1]: # in reverse (chronological) order
df_subset = foxnews[foxnews['month_year']==time].copy()
bag = df_subset['title'].str.cat(sep = ' ')
tokens = process(bag)
frames.append(pd.DataFrame.from_dict(dict(Counter(tokens)), orient='index', columns=[str(time)]))end_df = merge(word_df, frames)
end_df = end_df.fillna(0)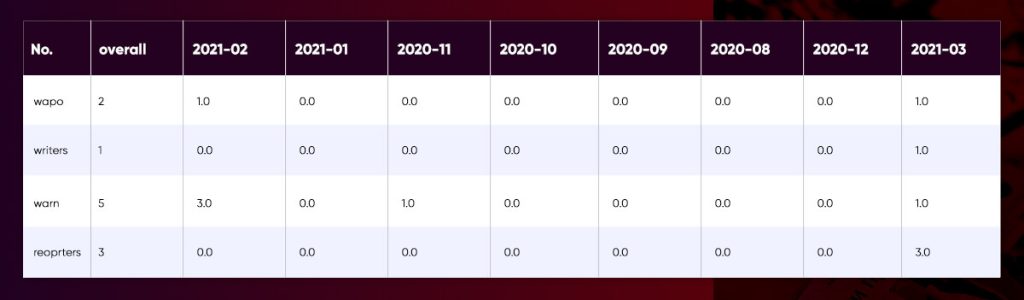
Though such a dataset is useful when comparing month to month, this would be more convenient to visualise and show the change in Tableau in a lengthy format – therefore the transformation:
df_long_temp = end_df.drop(columns='overall').reset_index()
df_long = pd.melt(df_long_temp,id_vars=['index'],var_name='year', value_name='frequency')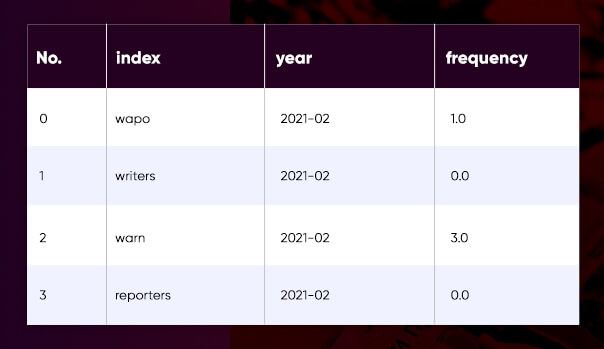
Here’s a link to a tutorial on how to animate the Tableau visualisation.
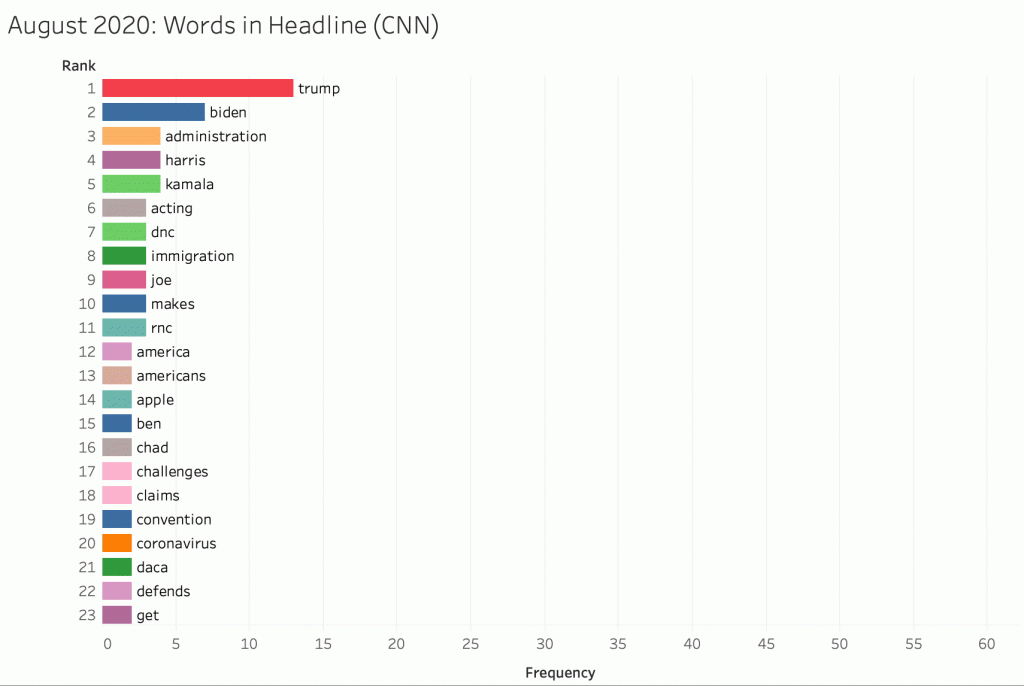
Beginning in the election month, we observe references of Biden rise quickly, while “Trump” falls off the list totally in March, and attention to migrant children rises with “border.”
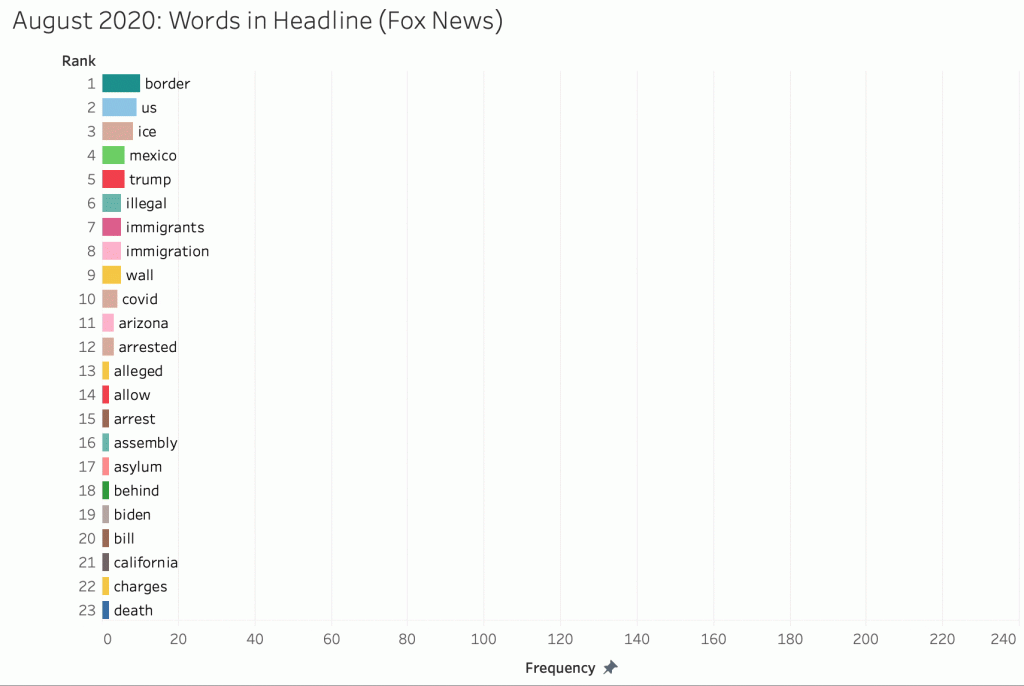
Since the election, “Biden” has taken the lead, but the attention didn’t build up until the start of 2021 when “crisis” and “surge” began to dominate the media.
Keywords in Articles
To see which words in the articles might have greater meaning, we have used TF-IDF again, which evaluates both the value of a term in the document (in this example, a specific news story) and its relevance in the whole corpus, with the all-too-common words weighted less. We also threw in some stops to the mix.
There are various ways to achieve this, but in this case, we tried to pool the top ten terms (ordered by their TF-IDF weights) across articles to analyze the differences in each publication’s total vocabulary.
def stemming(token):
global stopwords_tokenized
stemmer = SnowballStemmer("english")
if (token in stopwords_tokenized):
return token
else:
return stemmer.stem(token)
# a slightly revised process function
def preprocess(text):
tokens = []
for sentence in nltk.sent_tokenize(text):
for word in nltk.word_tokenize(sentence):
token = word.lower().replace("'", "")
if ('covid-19' in token) or ('coronavirus' in token):
tokens.append('covid')
else:
tokens.append(token)
tokens_filtered = [t for t in tokens if re.search('[a-zA-Z]', t)]
stems = [stemming(t) for t in tokens_filtered]
return stems
articles = df.content.tolist()
tfidf_vectorizer = TfidfVectorizer(max_df=0.8, min_df=5, max_features=200000, stop_words=stopwords_tokenized,\
strip_accents='unicode', use_idf=True, tokenizer=preprocess, ngram_range=(1,2))
tfidf_matrix = tfidf_vectorizer.fit_transform(articles)
terms = tfidf_vectorizer.get_feature_names()
# pool top 10 keywords in each news article
keywords = []
for row in range(tfidf_matrix.shape[0]):
for i in tfidf_matrix[row].toarray()[0].argsort()[::-1][:10]:
keywords.append(terms[i])We might notice the similarities in keywords this way:
set(fn_content_words).intersection(set(cnn_content_words))# word endings altered due to stemming
{'administr', #administration
'biden',
'bill',
'children',
'democrat',
'facil', # facilities
'ice',
'mayorka',
'mexico',
'migrant',
'polic', # policy
'polici', # policies
'presid', # president
'republican',
'senat', # senate
'trump',
'unaccompani', # unaccompanied
'wolf'} # Chad WolfWe may utilise — to see which words were adopted by one but not the other.
set(fn_content_words).difference(set(cnn_content_words))
set(cnn_content_words).difference(set(fn_content_words))The above analysis shows that Fox News’ keywords include arrest, caravan, legally questionable, wall, Latino, and various states such as Arizona and Texas. In contrast, CNN’s keywords included American, Black, China, White, Latino, women, campaign, protest, and worker, which did not appear to significantly impact Fox News.
Sentiment analysis, topic detection, or more specific content analysis, such as comparing organizations’ nouns, modals, quotations, or lexical diversity, could be used as a further step.
For any Queries, Contact 3i Data Scraping!!













What Will We Do Next?
- Our representative will contact you within 24 hours.
- We will collect all the necessary requirements from you.
- The team of analysts and developers will prepare estimation.
- We keep confidentiality with all our clients by signing NDA.



