How to Build a Web Scraping API using Java, Spring Boot, and Jsoup?
This blog show how to practically build a web scraping API using Java, Spring Boot, and Jsoup and how 3i Data Scraping can help you with that.
Our achievements in the field of business digital transformation.





Overview
At 3i Data Scraping, we will create an API for scraping data from a couple of vehicle selling sites as well as extract the ads depending on vehicle models that we pass for an API. This type of API could be used from the UI as well as show different ads from various websites in one place.
Web Scraping
- IntelliJ as IDE of option
- Maven 3.0+ as a building tool
- JDK 1.8+
Getting Started
Initially, we require to initialize the project using spring initializer
It can be done through visiting http://start.spring.io/
Ensure to choose the given dependencies also:
- Lombok: Java library, which makes a code cleaner as well as discards boilerplate codes.
- Spring WEB: It is product of Spring community, with focus on making document-driven web services.
After starting the project, we would be utilizing two-third party libraries JSOUP as well as Apache commons. The dependencies could be added in the pom.xml file.
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-lang3 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.11</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
Analyze HTML to Extract Data
Before starting the implementation of API, we need to visit https://riyasewana.com/ and https://ikman.lk/ to locate data, which we need to extract from these sites.
We can perform that by launching the given sites on browser as well as inspect HTML code with Dev tools.
If you are using Chrome, just right click on the page as well as choose inspect.
Its result will look like:
Build A Web Scraping API
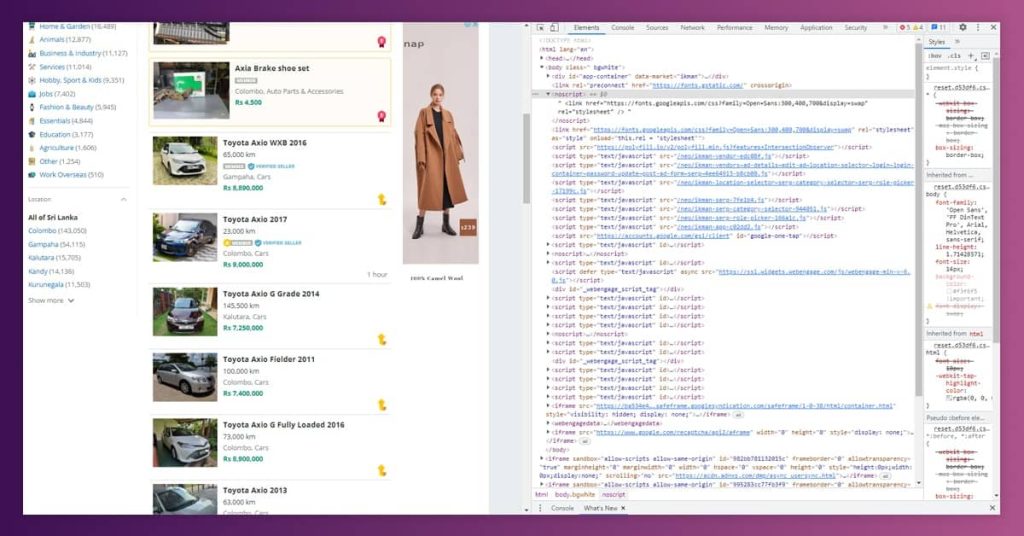
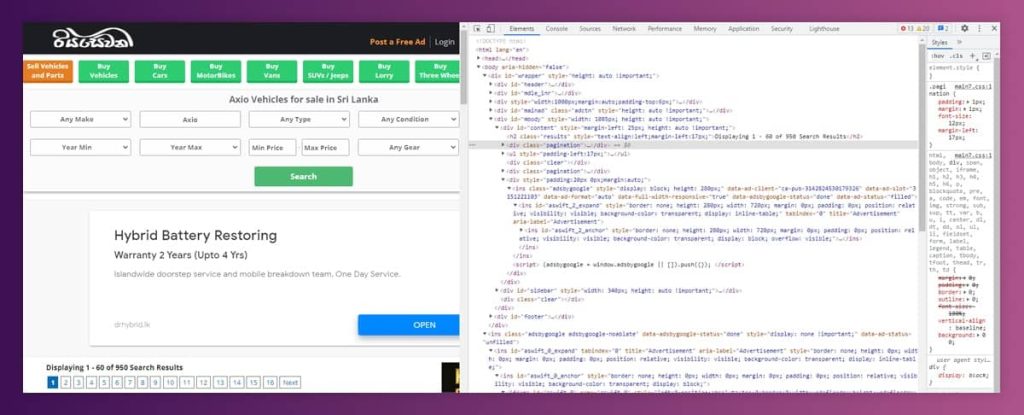
After opening different websites we need to navigate through HTML for identifying a DOM where the ad list is positioned. These identified elements would be utilized in the Spring boot project for getting relevant data.
From navigating through ikman.lk HTML, it’s easy to see a list of ads are positioned under a class name’s list — 3NxGO.
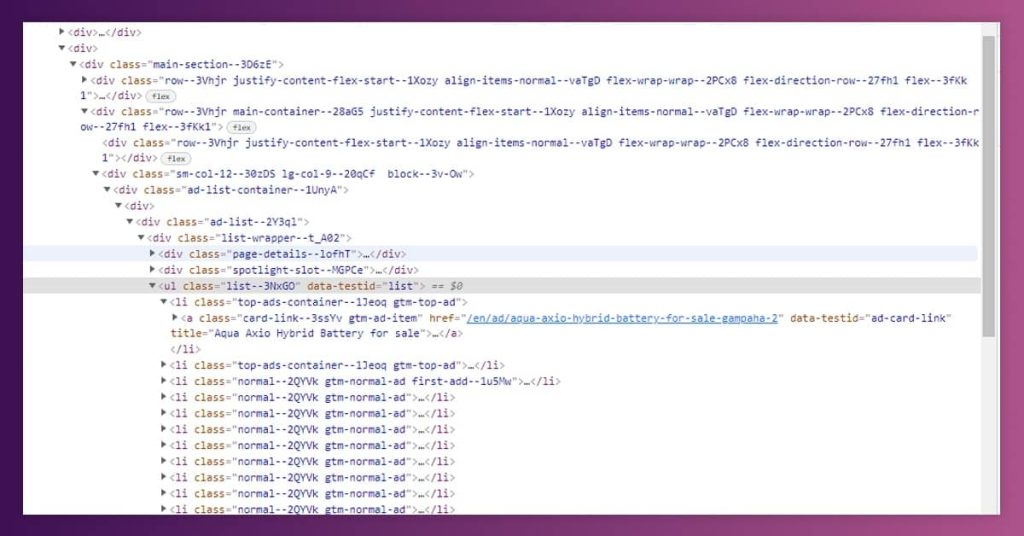
After that, we need to perform the same with Riyasewana.com, where ad data is positioned under a div with id content.
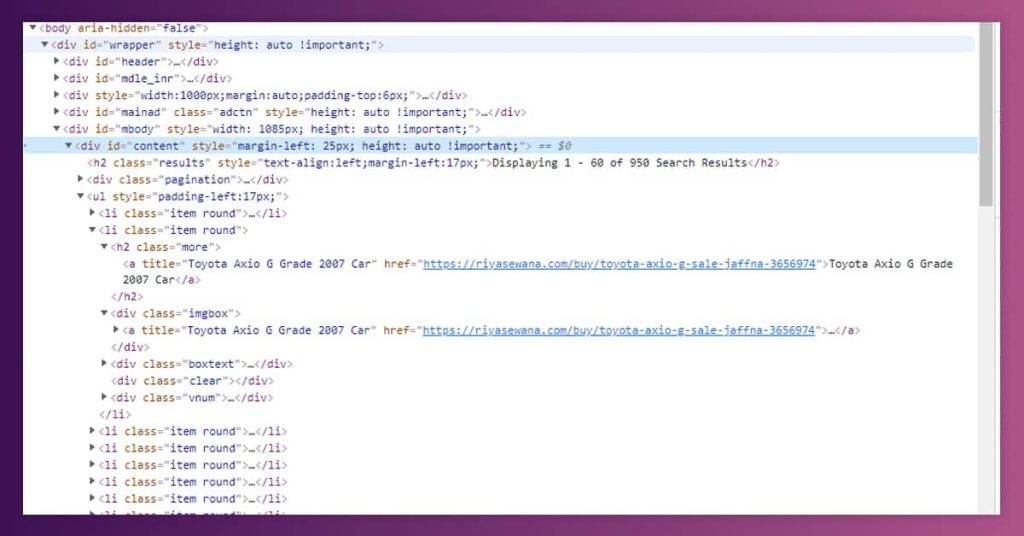
After recognizing all the data, let’s create our API for scraping the data!!!.
Implementation
Initially, we need to define website URLs in the file called application.yml/application.properties
website:
urls: https://ikman.lk/en/ads/sri-lanka/vehicles?sort=relevance&buy_now=0&urgent=0&query=,https://riyasewana.com/search/
After that, create an easy model class for mapping data using HTML.
package com.scraper.api.model;
import lombok.Data;
@Data
public class ResponseDTO {
String title;
String url;
}
In the given code, we utilize Data annotation generation setters and getters for attribute.
After that, it’s time to create a service layer as well as scrape data from these websites.
package com.scraper.api.service;
import com.scraper.api.model.ResponseDTO;
import org.apache.commons.lang3.StringUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
@Service
public class ScraperServiceImpl implements ScraperService {
//Reading data from property file to a list
@Value("#{'${website.urls}'.split(',')}")
List<String> urls;
@Override
public Set<ResponseDTO> getVehicleByModel(String vehicleModel) {
//Using a set here to only store unique elements
Set<ResponseDTO> responseDTOS = new HashSet<>();
//Traversing through the urls
for (String url: urls) {
if (url.contains("ikman")) {
//method to extract data from Ikman.lk
extractDataFromIkman(responseDTOS, url + vehicleModel);
} else if (url.contains("riyasewana")) {
//method to extract Data from riyasewana.com
extractDataFromRiyasewana(responseDTOS, url + vehicleModel);
}
}
return responseDTOS;
}
private void extractDataFromRiyasewana(Set<ResponseDTO> responseDTOS, String url) {
try {
//loading the HTML to a Document Object
Document document = Jsoup.connect(url).get();
//Selecting the element which contains the ad list
Element element = document.getElementById("content");
//getting all the <a> tag elements inside the content div tag
Elements elements = element.getElementsByTag("a");
//traversing through the elements
for (Element ads: elements) {
ResponseDTO responseDTO = new ResponseDTO();
if (!StringUtils.isEmpty(ads.attr("title")) ) {
//mapping data to the model class
responseDTO.setTitle(ads.attr("title"));
responseDTO.setUrl(ads.attr("href"));
}
if (responseDTO.getUrl() != null) responseDTOS.add(responseDTO);
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
private void extractDataFromIkman(Set<ResponseDTO> responseDTOS, String url) {
try {
//loading the HTML to a Document Object
Document document = Jsoup.connect(url).get();
//Selecting the element which contains the ad list
Element element = document.getElementsByClass("list--3NxGO").first();
//getting all the <a> tag elements inside the list- -3NxGO class
Elements elements = element.getElementsByTag("a");
for (Element ads: elements) {
ResponseDTO responseDTO = new ResponseDTO();
if (StringUtils.isNotEmpty(ads.attr("href"))) {
//mapping data to our model class
responseDTO.setTitle(ads.attr("title"));
responseDTO.setUrl("https://ikman.lk"+ ads.attr("href"));
}
if (responseDTO.getUrl() != null) responseDTOS.add(responseDTO);
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
After writing the scraping logic for a service layer, we can now implement the RestController for fetching data from these websites.
package com.scraper.api.controller;
import com.scraper.api.model.ResponseDTO;
import com.scraper.api.service.ScraperService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Set;
@RestController
@RequestMapping(path = "/")
public class ScraperController {
@Autowired
ScraperService scraperService;
@GetMapping(path = "/{vehicleModel}")
public Set<ResponseDTO> getVehicleByModel(@PathVariable String vehicleModel) {
return scraperService.getVehicleByModel(vehicleModel);
}
}
When everything is completed. We need to Run this Project as well as test this API!
Go to the RestClient and call API by offering a vehicle model.
For Example: http://localhost:8080/axio
Here, you can observe that you have all the ad URLs as well as titles associated to given vehicle models from both these websites.
Conclusion
In this blog, you have learned about how to manipulate the HTML document using jsoup as well as Spring boot to extract data from these two websites. The next step will be:
Improving this API to help pagination in these websites.
Implementing the UI for consuming the API
For more information on building Web Scraping API with Java, Spring Boot, or Jsoup, you can contact 3i Data Scraping or ask for a free quote!
Build A Web Scraping API Using Java, Spring Boot, And Jsoup?













What Will We Do Next?
- Our representative will contact you within 24 hours.
- We will collect all the necessary requirements from you.
- The team of analysts and developers will prepare estimation.
- We keep confidentiality with all our clients by signing NDA.



