How to Extract Amazon Product Prices Data with Python 3?
Web data scraping assists in automating web scraping from websites. In this blog, we will create an Amazon product data scraper for scraping product prices and details. We will create this easy web extractor using SelectorLib and Python and run that in the console.
Our achievements in the field of business digital transformation.




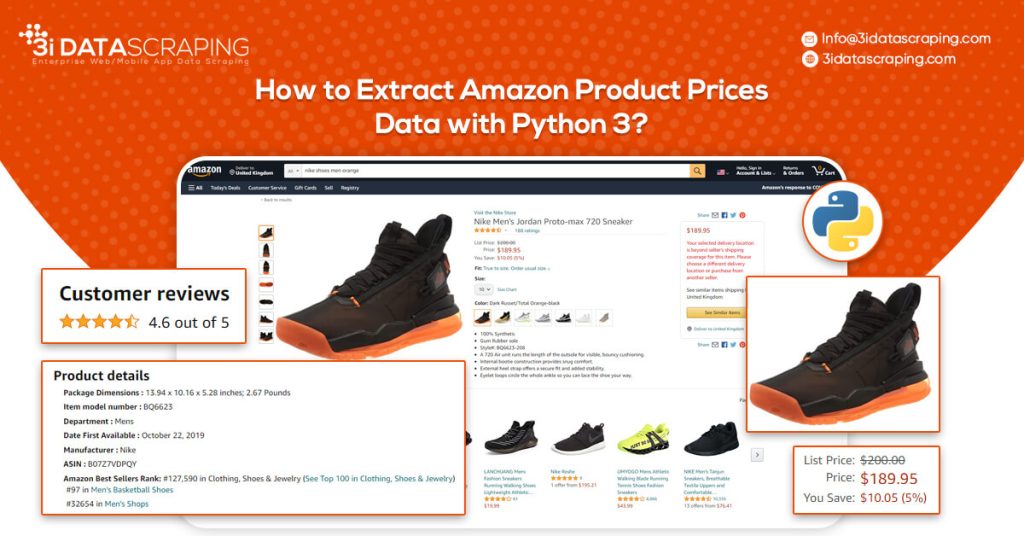
How to Extract Amazon Product Data from Amazon Product Pages?
- Markup all data fields to be extracted using Selectorlib
- Then copy as well as run the given code
We will utilize Python 3 for the Amazon Data Scraper. This code won’t run in case, you use Python 2.7. You require a computer having Python 3 as well as PIP installed.
Follow the guide given to setup the computer as well as install packages in case, you are using Windows.
Packages for Installing Amazon Data Scraping
Python Requests for making requests as well as download HTML content from Amazon’s product pages
SelectorLib python packages to scrape data using a YAML file that we have created from webpages that we download
Using pip3,
Extract Product Data from Amazon Product Pages
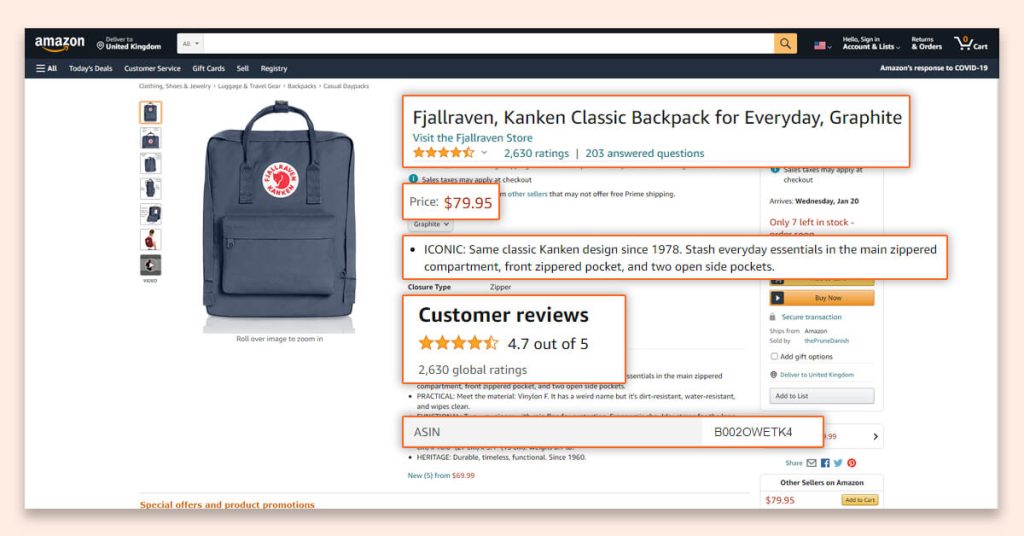
An Amazon product pages extractor will extract the following data from product pages.
- Product Name
- Pricing
- Short Description
- Complete Product Description
- Ratings
- Images URLs
- Total Reviews
- Optional ASINs
- Link to Review Pages
- Sales Ranking
Markup Data Fields with Selectorlib
As we have marked up all the data already, you can skip the step in case you wish to have rights of the data.
Let’s save it as the file named selectors.yml in same directory with our code
name:
The markup will look like this:
Selectorlib is the combination of different tools for the developers, who make marking up as well as scraping data from pages easier. The Chrome Extension of Selectorlib helps you mark the data, which you require to scrape and create the XPaths or CSS Selectors required to scrape the data and previews about how that data will look like.
Looking For Amazon Product Data?
Amazon Scraping Code
Make a folder named amazon-scraper as well as paste the selectorlib yaml template file like selectors.yml
Let’s make a file named amazon.py as well as paste the code given below in it. It includes:
- Read the listing of Amazon Product URLs from the file named urls.txt
- Extract the Data
- Save Data in the JSON Format
Run the Amazon Product Pages Scraper
Get a complete code from the link Github –
https://www.3idatascraping.com/contact-us/
You may start the scraper through typing this command:
When scraping gets completed, then you can see the file named output.jsonl having the data. Let’s see the example of it:
https://www.amazon.com/HP-Computer-Quard-Core-Bluetooth-Accessories/dp/B085383P7M/
Scraping Amazon Products from Search Results Pages
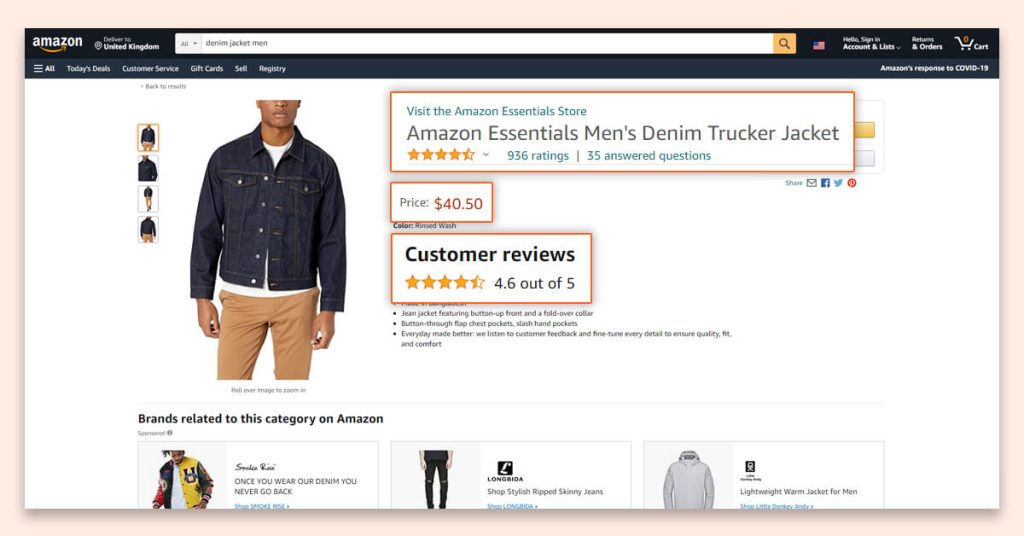
The Amazon search results pages scraper will extract the following data from different search result pages:
- Product’s Name
- Pricing
- URL
- Ratings
- Total Reviews
The code and steps for extracting the search results is similar to a product pages scraper.
Markup Data Fields with Selectorlib
Here is a selectorlib yml file. Let’s calls that search_results.yml
The Code
This code is nearly matching to the earlier scraper, excluding that we repeat through every product as well as save them like a separate line.
Let’s make a file searchresults.py as well as paste the code given in it. This is what a code does:
- Open the file named search_results_urls.txt as well as read the search results pages URLs
- Extract the data
- Then save to the JSON Line files named search_results_output.jsonl
Run an Amazon Scraper for Scraping Search Results
You can begin your scraper through typing this command:
When the scraping is completed, you need to see the file named search_results_output.jsonl with the data.
The example of it is:
What Should You Do If You are Blocked When Scraping Amazon?
Amazon may consider you as the “BOT” in case, you start extracting hundreds of pages by the code given here. The thing is to avoid having flagged as a BOT while extracting as well as running the problems. How to cope with such challenges?
Imitate the human behavior to the maximum
As there is no assurance that you won’t get blocked. Just follow these tips about how to evade being blocked by the Amazon:
Use Proxies as well as Switch Them
Let us assume that we are extracting thousands of products on Amazon.com using a laptop that normally has only single IP address. Amazon would assume us as a bot because NO HUMAN visits thousands of product pages within minutes. To look like the human – make some requests to Amazon using the pool of proxies or IP Addresses. The key rule is to have only 1 IP address or proxy making not over 5 requests for Amazon in one minute. In case, you scrape around 100 pages for every minute, thenn we need around 100/5 = 20 Proxies.
Specify User Agents of the Newest Browsers as well as Switch Them
If you observe the code given, you would get a line in which we had set the User-Agent String for requests we are doing.
Like proxies, it’s good to get the pool of different User Agent Strings. So, ensure that you use user-agent strings for the popular and latest browsers as well as rotate these strings for every request you do to Amazon. It is a good idea of creating a grouping of (IP Address, User-Agent) so it looks human than the bot.
Decrease the Total ASINs Extracted Every Minute
You can also try to slow down the scrapping a bit for giving Amazon lesser chances of considering you as the bot. However, around 5 requests for every IP per minute isn’t throttling much. If you want to go quicker, add additional proxies. You can adjust the speed through decreasing or increasing the delay within the sleep functions.
Continue Retrying
Whenever you get blocked by the Amazon, ensure you retry the request. If you are looking at a code block given we have included 20 retries. Our codes retry immediately after scraping fails, you can do a better job by making the retry queues using the list, as well as retry them when all the products get scraped from the Amazon.
If you are looking to get Amazon product data and prices scraping using Python 3 then contact 3i Data Scraping!













What Will We Do Next?
- Our representative will contact you within 24 hours.
- We will collect all the necessary requirements from you.
- The team of analysts and developers will prepare estimation.
- We keep confidentiality with all our clients by signing NDA.



