How to Extract Email Addresses using Web Scraper?
As a startup, if you want to get more prospective leads, you might need to get the maximum number of business email addresses possible. This blog shows how to extract email scraping using a web scraper and how 3i Data Scraping can help you in that.
Our achievements in the field of business digital transformation.




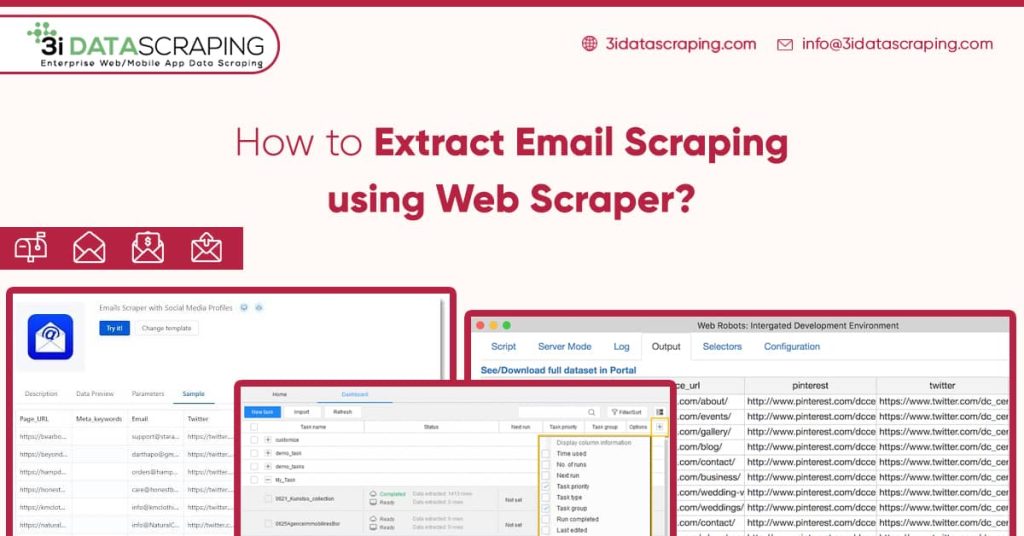
As a startup, if you want to get more prospective leads, you might need to get maximum business email addresses possible.
Although there are countless email scraping tools available, majority of them come with free usage limits. This tutorial would help you find emails addresses from websites anytime without any limits!
Looking for extracting email address data?
Stage 1: Import Modules
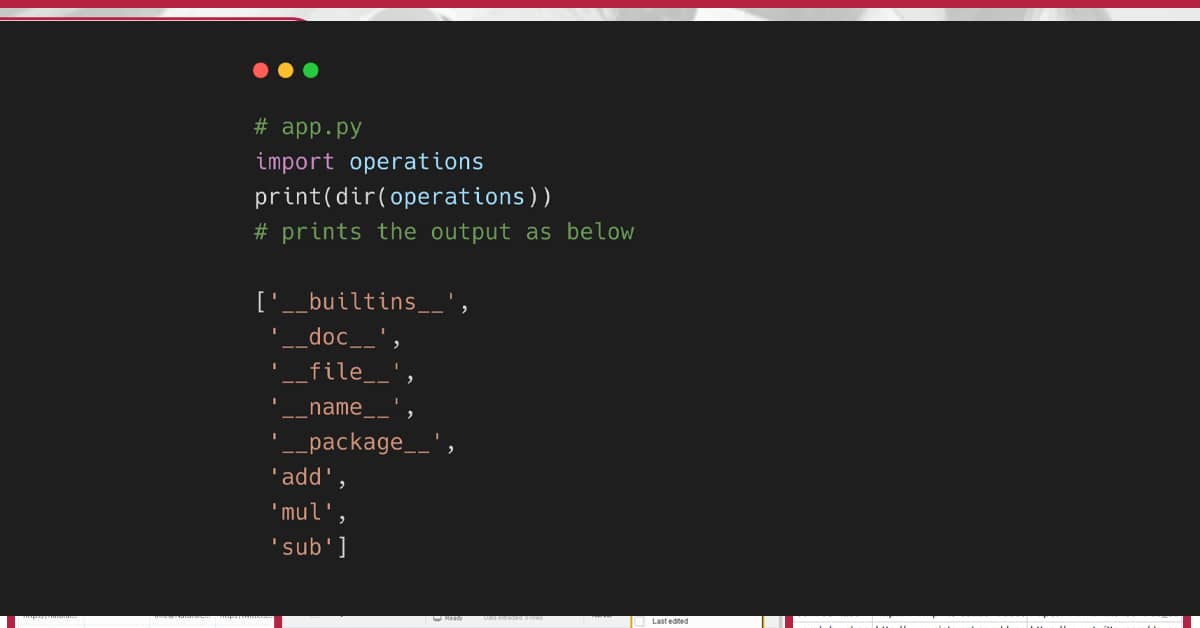
We have imported six modules for the given project.
import re import requests from urllib.parse import urlsplit from collections import deque from bs4 import BeautifulSoup import pandas as pd
- Re for consistent expression corresponding operations
- Requests to send HTTP requests
- Urlsplit to break URLs down into parts
- Deque is the list-like container having quick appends as well as pops at either end
- BeautifulSoup to pull data out from website HTML files
- Pandas to format emails in a DataFrame for more manipulation
Stage 2: Set Variables
After that, we reset a deque to save unscraped URLs, with a set for extracted URLs and a set to save emails extracted successfully from a website.
# read url from input
original_url = input("Enter the website url: ")
# to save urls to be scraped
unscraped = deque([original_url])
# to save scraped urls
scraped = set()
# to save fetched emails
emails = set()
Elements given in the Set are distinctive. Duplicate elements won’t be allowed.
Stage 3: Start Extracting
1. Initially, move the URL to scraped from unscraped.
while len(unscraped):
# move unsraped_url to scraped_urls set
url = unscraped.popleft() # popleft(): Remove and return an element from the left side of the deque
scraped.add(url)
2. After that, we utilize urlsplit to scrap various URL parts.
parts = urlsplit(url)
urlsplit()refunds a 5-tuple: (addressing network location, scheme, path, query, and fragment identifier).
Sample inputs and outputs for urlsplit()
Input: "https://www.google.com/example" Output: SplitResult(scheme='https', netloc='www.google.com', path='/example', query='', fragment='')
That way, we can get a base & path part for a website URL.
base_url = "{0.scheme}://{0.netloc}".format(parts)
if '/' in parts.path:
path = url[:url.rfind('/')+1]
else:
path = url
3. Send an HTTP GET request for a website.
print("Crawling URL %s" % url) # Optional
try:
response = requests.get(url)
except (requests.exceptions.MissingSchema, requests.exceptions.ConnectionError):
# ignore pages with errors and continue with next url
continue 4. Scrape all the email addresses from a response using regular expressions and add them to an email set.
# You may edit the regular expression as per your requirement
new_emails = set(re.findall(r"[a-z0-9\.\-+_]+@[a-z0-9\.\-+_]+\.com",
response.text, re.I)) # re.I: (ignore case)
emails.update(new_emails)In case, you are unfamiliar with Python’s regular regression, observe Python RegEx to get more details.
5. Discover all the linked URLs in a Website.
To do so, we need to make a BeautifulSoup for parsing an HTML document.
# create a beutiful soup for the html document
soup = BeautifulSoup(response.text, 'lxml')
After that, we can get all linked URLs within a document through getting an tag that shows a hyperlink.
for anchor in soup.find_all("a"):
# extract linked url from the anchor
if "href" in anchor.attrs:
link = anchor.attrs["href"]
else:
link = ''
# resolve relative links (starting with /)
if link.startswith('/'):
link = base_url + link
elif not link.startswith('http'):
link = path + link
Add a new url to unscraped queue in case, it was not with unscraped nor within scraped yet.
Also, we need to dismiss links including http://www.medium.com/file.gz which are incapable to get scraped.
if not link.endswith(".gz"):
if not link in unscraped and not link in scraped:
unscraped.append(link)Stage 4: Export Emails in the CSV File
After effectively extracting emails from a website, we could export emails to the CSV file.
df = pd.DataFrame(emails, columns=["Email"]) # replace with column name you prefer
df.to_csv('email.csv', index=False)
In case, you are utilizing Google Colaboratory, you could download a file to local machines through:
from google.colab import files
files.download("email.csv")
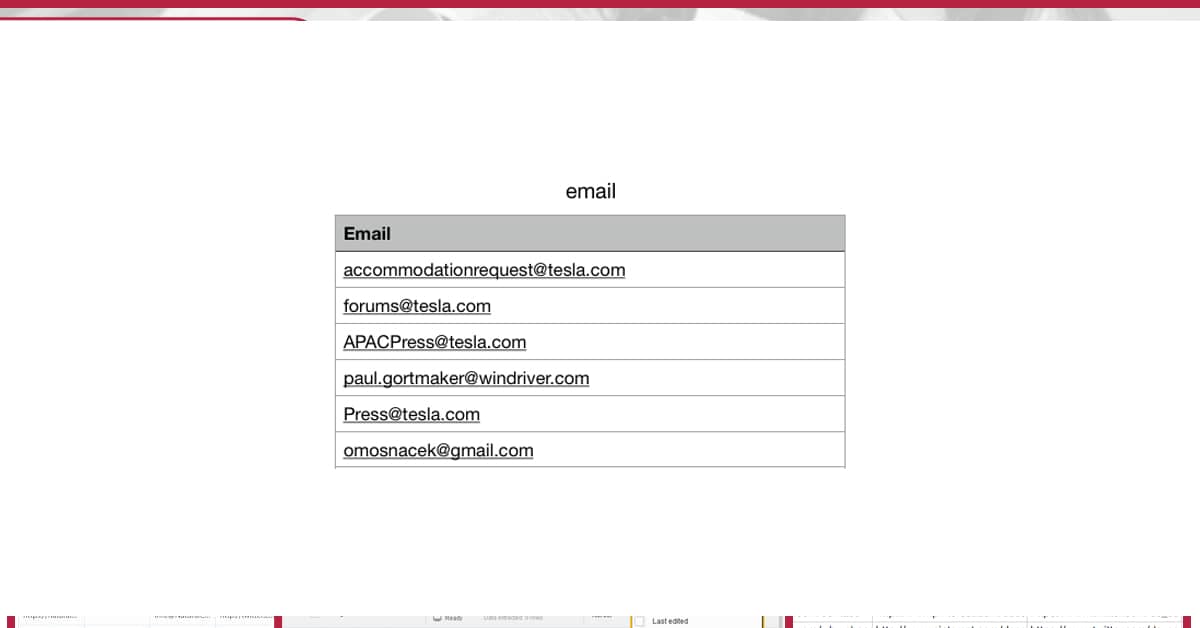
Here is the sample output file in CSV format:
Complete Code
Here is the complete code of all the procedure done:
import re
import requests
from urllib.parse import urlsplit
from collections import deque
from bs4 import BeautifulSoup
import pandas as pd
from google.colab import files
original_url = input("Enter the website url: ")
unscraped = deque([original_url])
scraped = set()
emails = set()
while len(unscraped):
url = unscraped.popleft()
scraped.add(url)
parts = urlsplit(url)
base_url = "{0.scheme}://{0.netloc}".format(parts)
if '/' in parts.path:
path = url[:url.rfind('/')+1]
else:
path = url
print("Crawling URL %s" % url)
try:
response = requests.get(url)
except (requests.exceptions.MissingSchema, requests.exceptions.ConnectionError):
continue
new_emails = set(re.findall(r"[a-z0-9\.\-+_]+@[a-z0-9\.\-+_]+\.com", response.text, re.I))
emails.update(new_emails)
soup = BeautifulSoup(response.text, 'lxml')
for anchor in soup.find_all("a"):
if "href" in anchor.attrs:
link = anchor.attrs["href"]
else:
link = ''
if link.startswith('/'):
link = base_url + link
elif not link.startswith('http'):
link = path + link
if not link.endswith(".gz"):
if not link in unscraped and not link in scraped:
unscraped.append(link)
df = pd.DataFrame(emails, columns=["Email"])
df.to_csv('email.csv', index=False)
files.download("email.csv")



