




With this tutorial blog, you can use Python to Scrape Data from all Facebook Profiles or Pages. The data you would be scraping from the predefined amounts of posts include:
- Post URLs
- Post Media URLs
- Post Texts
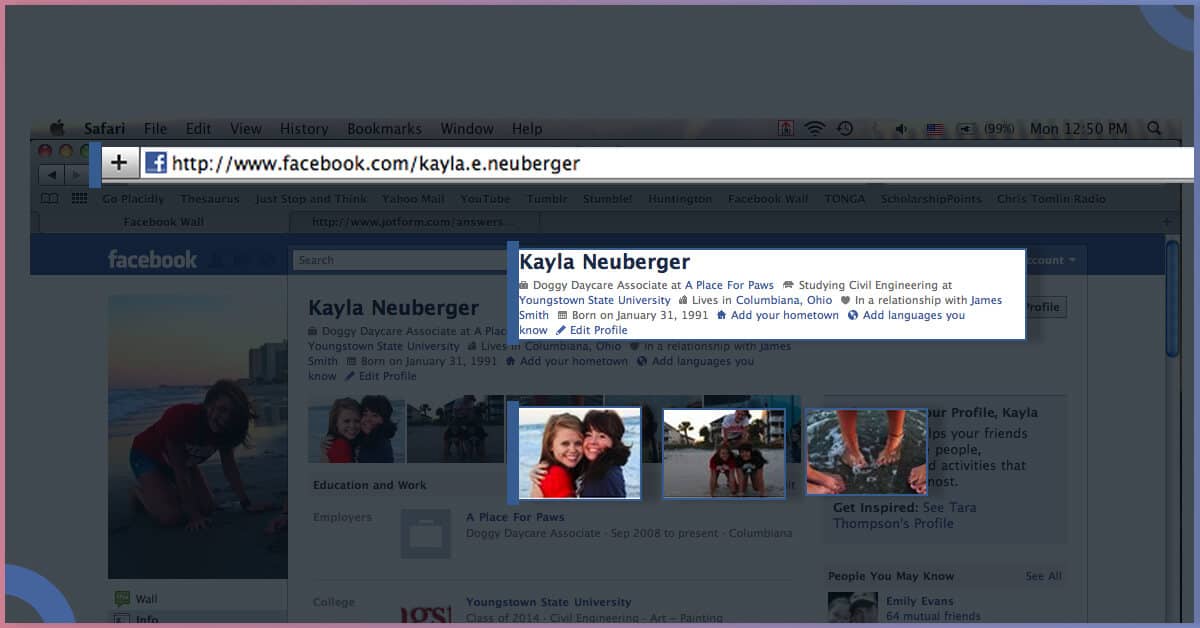
You would be scraping comments from different posts as well as from every comment:
- Profile’s Name
- Comment Text
- Profile URLs
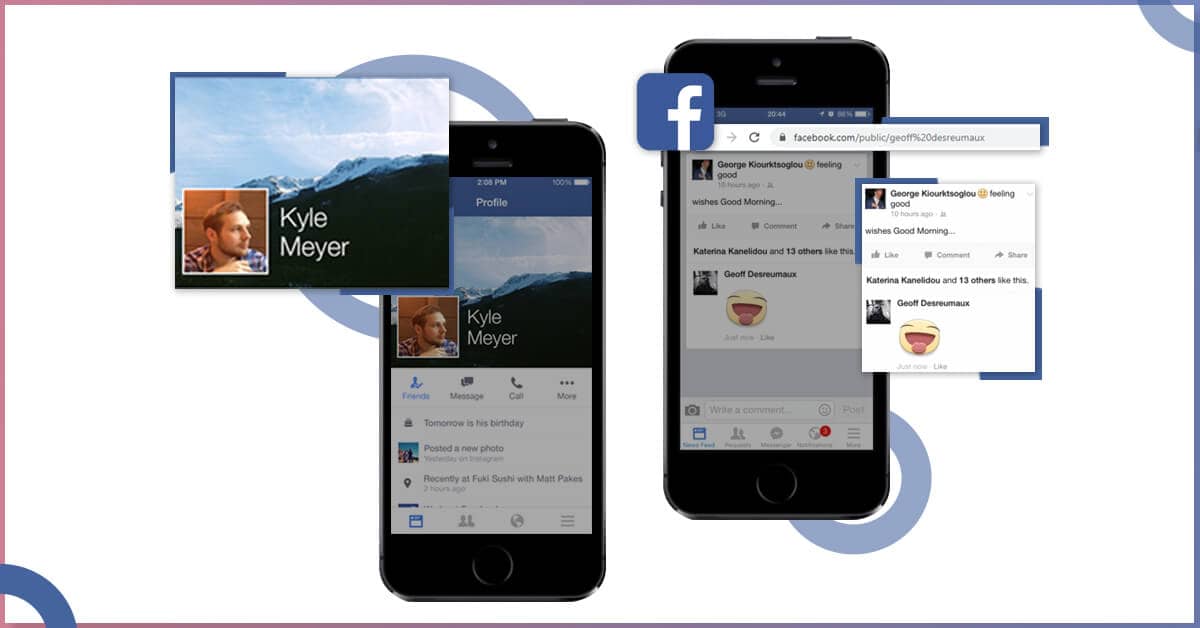
Certainly, there are a lot more, which can be scraped from Facebook however for this tutorial blog it would be sufficient.
Python Packages
In this tutorial blog, you would require the following Python packages:
- bs4 (BeautifulSoup)
- collections
- json
- logging
- re
- requests
- time
Remember to install all these packages in the Python Virtual Environment to complete this project; this is a superior practice.
Scrape Facebook Using Requests
Facebook is loaded with JavaScript however the requests package does not extract JavaScript; this only permits you to do easy web requests including POST and GET.
Note: In this tutorial blog, you will scrape Facebook’s mobile version, which will help you scrape the required data with easy requests.
How Will This Script Extract Facebook Mobile?
Initially, you are required to consider what script would be exactly performing. The script would:
- Get a listing of Facebook profile URLs from the file.
- Get credentials from the file for doing a login through the requests package.
- Create a login with the Session object through the requests package.
- For all profile URLs, we will scrape data from predefined amounts of posts.
This script would look like this on the key function:
if __name__ == "__main__":
logging.basicConfig(level=logging.INFO)
base_url = 'https://mobile.facebook.com'
session = requests.session()
# Extracts credentials for the login and all of the profiles URL to scrape
credentials = json_to_obj('credentials.json')
profiles_urls = json_to_obj('profiles_urls.json')
make_login(session, base_url, credentials)
posts_data = None
for profile_url in profiles_urls:
posts_data = crawl_profile(session, base_url, profile_url, 25)
logging.info('[!] Scraping finished. Total: {}'.format(len(posts_data)))
logging.info('[!] Saving.')
save_data(posts_data)
You use the logging package for putting a few log messages on script executions so that you understand which the script is performing.
Then you describe the base_url, which would be Facebook’s mobile URL.
After scraping input data from the files, you perform a login, calling a function named make_login, which you will describe shortly.
After that, for all profile URLs in the input data, you want to extract data from a particular number of posts with the crawl_profile function.
As previously stated, this script would require to get data from different sources: the file having profile URLs as well as another one having credentials from the Facebook accounts to make login. Let’s describe a function, which will help you scrape data from the JSON files:
def json_to_obj(filename):
"""Extracts data from JSON file and saves it on Python object
"""
obj = None
with open(filename) as json_file:
obj = json.loads(json_file.read())
return obj
The function permits you to scrape data formatted in JSON and convert it into Python objects.
The files credentials.json and profiles_urls.json will have input data that the script requires.
profiles_urls.json:
[
"https://mobile.facebook.com/profileURL1/",
"https://mobile.facebook.com/profileURL2"
]
credentials.json:
{
"email":"username@mail.com",
"pass":"password"
}
You would need to replace the profiles URLs from which you wish to scrape data, as well as the Facebook account identifications from login.
Facebook Log In
To log in, you need to examine Facebook’s main page (mobile.facebook.com) on the mobile version to find the URLs of a form.
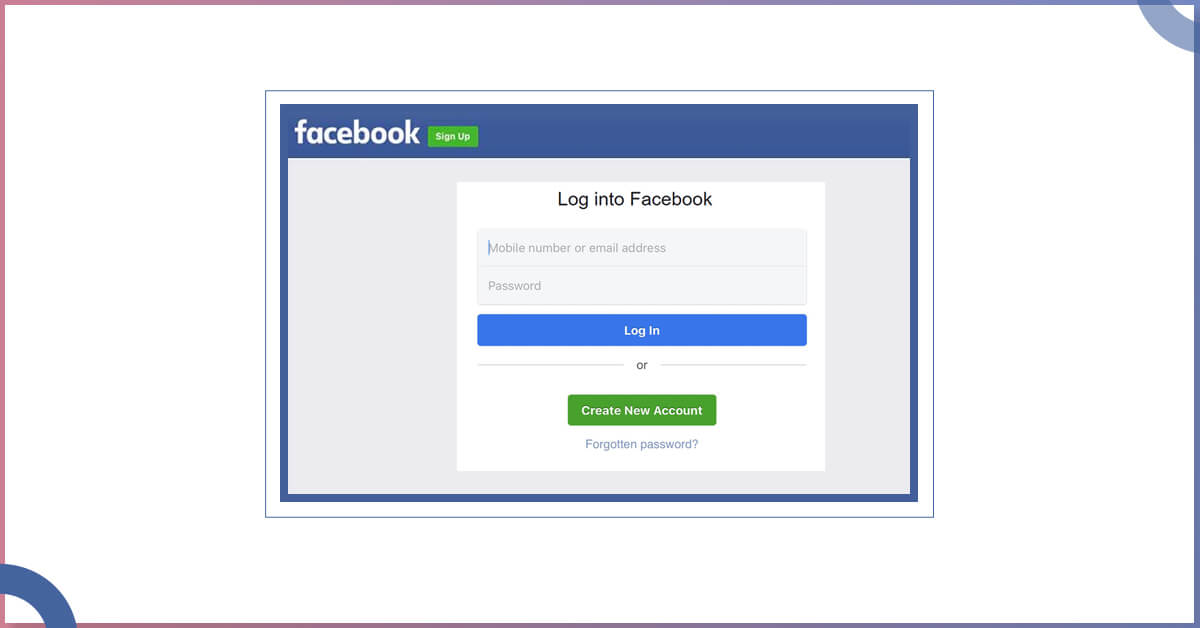
In case, we do the right clicking on “Log In” tab, you can have the form for which we need to send credentials:
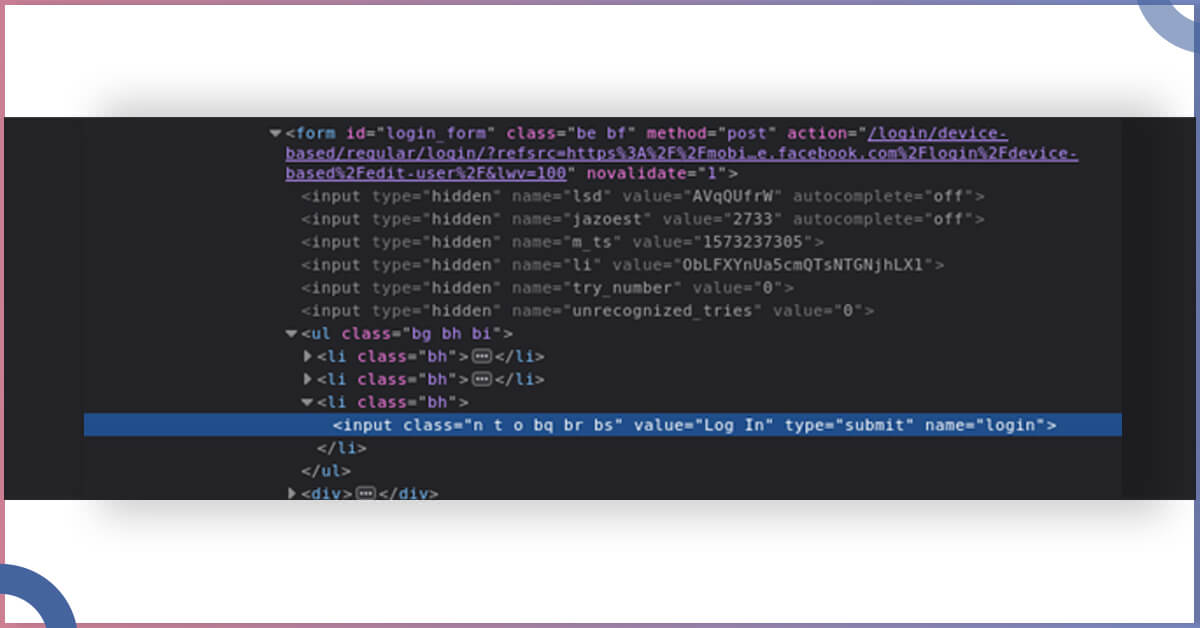
A URL from form element having the id=”login_form” is what you require to do login. Let’s describe the function which would assist you in this job:
def make_login(session, base_url, credentials):
"""Returns a Session object logged in with credentials.
"""
login_form_url = '/login/device-based/regular/login/?refsrc=https%3A'\
'%2F%2Fmobile.facebook.com%2Flogin%2Fdevice-based%2Fedit-user%2F&lwv=100'
params = {'email':credentials['email'], 'pass':credentials['pass']}
while True:
time.sleep(3)
logged_request = session.post(base_url+login_form_url, data=params)
if logged_request.ok:
logging.info('[*] Logged in.')
break
With the action URLs from form elements, you can create the POST request having requests package from Python. In case, the reply is OK is as you have successfully logged in, else you can wait a bit to try again.
With the action URLs from form elements, you can create the POST request having requests package from Python. In case, the reply is OK is as you have successfully logged in, else you can wait a bit to try again.
Crawling the Facebook’s Profile or Page
When you have logged in, then you require to crawl a Facebook page URL or profile to scrape public posts.
def crawl_profile(session, base_url, profile_url, post_limit):
"""Goes to profile URL, crawls it and extracts posts URLs.
"""
profile_bs = get_bs(session, profile_url)
n_scraped_posts = 0
scraped_posts = list()
posts_id = None
while n_scraped_posts < post_limit:
try:
posts_id = 'recent'
posts = profile_bs.find('div', id=posts_id).div.div.contents
except Exception:
posts_id = 'structured_composer_async_container'
posts = profile_bs.find('div', id=posts_id).div.div.contents
posts_urls = [a['href'] for a in profile_bs.find_all('a', text='Full Story')]
for post_url in posts_urls:
# print(post_url)
try:
post_data = scrape_post(session, base_url, post_url)
scraped_posts.append(post_data)
except Exception as e:
logging.info('Error: {}'.format(e))
n_scraped_posts += 1
if posts_completed(scraped_posts, post_limit):
break
show_more_posts_url = None
if not posts_completed(scraped_posts, post_limit):
show_more_posts_url = profile_bs.find('div', id=posts_id).next_sibling.a['href']
profile_bs = get_bs(session, base_url+show_more_posts_url)
time.sleep(3)
else:
break
return scraped_posts
First you need to save results of get_bs function in the profile_bs variable. The get_bs function gets the Session object as well as the URL variable:
def get_bs(session, url):
"""Makes a GET requests using the given Session object
and returns a BeautifulSoup object.
"""
r = None
while True:
r = session.get(url)
time.sleep(3)
if r.ok:
break
return BeautifulSoup(r.text, 'lxml')
This get_bs function would make the GET request through a Session object, in case, the request codes are OK and after that, we return the BeautifulSoup object made with a response.
Let’s break down the crawl_profile function:
When you have a profile_bs variable, then you describe variables for total posts extracted, the posts as well as posts ids.
After that, you open the while loop which will repeat always which the n_scraped_posts variables are less than the post_limit variables.
Within this loop, you just try and find out the HTML elements which hold all the elements whereas these posts are. In case, a Facebook URL is the Facebook page, the posts would be on an element having an id=’recent’ however, if a Facebook URL is the person’s profile, these posts would be on an element with id=’structured_composer_async_container’.
When you know these elements where these posts are, then you can scrape the URLs.
After that, for all post URLs which you have found, just call a scrape_post function as well as add that results to scraped_posts list.
In case, you have touched the predefined amounts of posts, you have broken the while loop.
Scrape Data from Different Facebook Posts
Let’s observe the function which will permit you to begin the actual scraping:
def scrape_post(session, base_url, post_url):
"""Goes to post URL and extracts post data.
"""
post_data = OrderedDict()
post_bs = get_bs(session, base_url+post_url)
time.sleep(5)
# Here we populate the OrderedDict object
post_data['url'] = post_url
try:
post_text_element = post_bs.find('div', id='u_0_0').div
string_groups = [p.strings for p in post_text_element.find_all('p')]
strings = [repr(string) for group in string_groups for string in group]
post_data['text'] = strings
except Exception:
post_data['text'] = []
try:
post_data['media_url'] = post_bs.find('div', id='u_0_0').find('a')['href']
except Exception:
post_data['media_url'] = ''
try:
post_data['comments'] = extract_comments(session, base_url, post_bs, post_url)
except Exception:
post_data['comments'] = []
return dict(post_data)
The function begins making an OrderedDict object which would be a one that holds post data:
- Comments
- Post Media URLs
- Post Texts
- Post URL
Initially, you require a post HTML code within the BeautifulSoup object so utilize get_bs function for it.
As you already understand the post URLs, at that point you require to add that to a post_data object.
For scraping the post texts, you require to get the post key elements, as follows:
try:
post_text_element = post_bs.find('div', id='u_0_0').div
string_groups = [p.strings for p in post_text_element.find_all('p')]
strings = [repr(string) for group in string_groups for string in group]
post_data['text'] = strings
except Exception:
post_data['text'] = []
Then you search for a div having all text, however these elements can have many (p) tags having text so that you repeat overall as well as scrape the text.
Then, you scrape post media URLs. Facebook posts have either video or images or even that might be only the text:
try:
post_data['media_url'] = post_bs.find('div', id='u_0_0').find('a')['href']
except Exception:
post_data['media_url'] = ''
In the end, call a function extract_comments for scraping remaining data:
try:
post_data['comments'] = extract_comments(session, base_url, post_bs, post_url)
except Exception:
post_data['comments'] = []
Scraping Facebook Comments
The function is bigger for the tutorial so here you repeat over the while loop till there are more comments extracted:
def extract_comments(session, base_url, post_bs, post_url):
"""Extracts all coments from post
"""
comments = list()
show_more_url = post_bs.find('a', href=re.compile('/story\.php\?story'))['href']
first_comment_page = True
logging.info('Scraping comments from {}'.format(post_url))
while True:
logging.info('[!] Scraping comments.')
time.sleep(3)
if first_comment_page:
first_comment_page = False
else:
post_bs = get_bs(session, base_url+show_more_url)
time.sleep(3)
try:
comments_elements = post_bs.find('div', id=re.compile('composer')).next_sibling\
.find_all('div', id=re.compile('^\d+'))
except Exception:
pass
if len(comments_elements) != 0:
logging.info('[!] There are comments.')
else:
break
for comment in comments_elements:
comment_data = OrderedDict()
comment_data['text'] = list()
try:
comment_strings = comment.find('h3').next_sibling.strings
for string in comment_strings:
comment_data['text'].append(string)
except Exception:
pass
try:
media = comment.find('h3').next_sibling.next_sibling.children
if media is not None:
for element in media:
comment_data['media_url'] = element['src']
else:
comment_data['media_url'] = ''
except Exception:
pass
comment_data['profile_name'] = comment.find('h3').a.string
comment_data['profile_url'] = comment.find('h3').a['href'].split('?')[0]
comments.append(dict(comment_data))
show_more_url = post_bs.find('a', href=re.compile('/story\.php\?story'))
if 'View more' in show_more_url.text:
logging.info('[!] More comments.')
show_more_url = show_more_url['href']
else:
break
return comments
You require to be well aware that if you scrape the initial comments page or following pages then you can define the first_comment_page variables as True.
Just look in case there is any link of “View More Comments” as it will let us know if you are repeating over the loop or not:
show_more_url = post_bs.find('a', href=re.compile('/story\.php\?story'))['href']Within the key loop of a function, initially you need to check values of first_comment_page, in case, it is True, you scrape comments from the current page, or you make the requests to URL of “View More Comments”:
if first_comment_page:
first_comment_page = False
else:
post_bs = get_bs(session, base_url+show_more_url)
time.sleep(3) Value 1,229.01 Mil.Baht
After that, choose all HTML elements which have comments. You require to perform a second clicking on a comment and you will observe that every comment is within the div having the 17-digit ID:
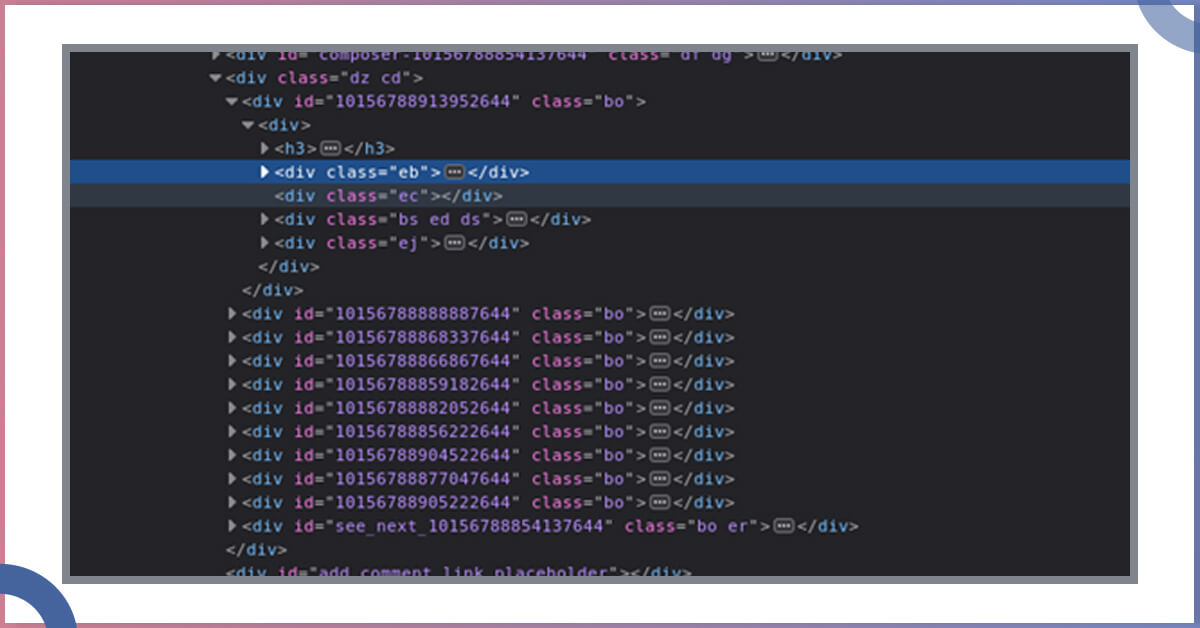
By understanding this, you can choose all elements like this:
try:
comments_elements = post_bs.find('div', id=re.compile('composer')).next_sibling\
.find_all('div', id=re.compile('^\d+'))
except Exception:
pass
if len(comments_elements) != 0:
logging.info('[!] There are comments.')
else:
break
In case, you are unable to get elements, it means that no elements are there. Now, for all comments, you need to make the OrderedDict object where you would save data from the comment:
for comment in comments_elements:
comment_data = OrderedDict()
comment_data['text'] = list()
try:
comment_strings = comment.find('h3').next_sibling.strings
for string in comment_strings:
comment_data['text'].append(string)
except Exception:
pass
try:
media = comment.find('h3').next_sibling.next_sibling.children
if media is not None:
for element in media:
comment_data['media_url'] = element['src']
else:
comment_data['media_url'] = ''
except Exception:
pass
comment_data['profile_name'] = comment.find('h3').a.string
comment_data['profile_url'] = comment.find('h3').a['href'].split('?')[0]
comments.append(dict(comment_data))
Within this loop, you need to scrape comment text, searching for a HTML element having text, because in text of a post, you require to get all elements having strings as well as add every string into the list:
try:
comment_strings = comment.find('h3').next_sibling.strings
for string in comment_strings:
comment_data['text'].append(string)
except Exception:
pass
After that, you require a media URL:
try:
media = comment.find('h3').next_sibling.next_sibling.children
if media is not None:
for element in media:
comment_data['media_url'] = element['src']
else:
comment_data['media_url'] = ''
except Exception:
pass
When you get the data you require a profile name as well as profile URL, those you could find like this:
comment_data['profile_name'] = comment.find('h3').a.string
comment_data['profile_url'] = comment.find('h3').a['href'].split('?')[0]
When you get all data then you can have from the comment, then add data into the comment list. After that, you require to check in case, there is the link called “Show more comments”:
show_more_url = post_bs.find('a', href=re.compile('/story\.php\?story'))
if 'View more' in show_more_url.text:
logging.info('[!] More comments.')
show_more_url = show_more_url['href']
else:
break
A loop which is scraping the comments would stop in case, it cannot get more comments as well as a loop scraping the post data would stop after that reaches the given posts limit.
















