How to Extract Yahoo Finance Data with Stock Prices, Price Change, Bids, and more.
Our achievements in the field of business digital transformation.





The share market is a huge database for technology companies with millions of records that are getting updated constantly! As there are numerous companies, which offer financial data, this is generally done using real-time data scraping API, as well as APIs, which are available with their premium forms. Yahoo Finance is a reliable resource of share market data. This is a premium form as Yahoo is also having a Yahoo Finance API. As a substitute, you can have free access to any company’s stock data on a website.
Though it is very popular amongst the stock traders, this has persevered in the market while many big-size competitors like Google Finance are unsuccessful. For people interested in succeeding in the stock markets, Yahoo offers the most contemporary news on a stock market as well as firms.
Steps of Extracting Yahoo Finance
- Make an URL of search result pages from Yahoo Finance.
- Download HTML of search result pages with Python requests.
- Scrolling the page with LXML-LXML as well as help you navigate an HTML tree structure through Xpaths. We have well-defined the Xpaths for details needed for a code.
- Save downloaded data into the JSON file.
We would scrape the given data fields:
You would require to install the Python 3 packages to download as well as parse an HTML file.
The Script We Have Used
from lxml import html
import requests
import json
import argparse
from collections import OrderedDict
def get_headers():
return {"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-GB,en;q=0.9,en-US;q=0.8,ml;q=0.7",
"cache-control": "max-age=0",
"dnt": "1",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36"}
def parse(ticker):
url = "http://finance.yahoo.com/quote/%s?p=%s" % (ticker, ticker)
response = requests.get(
url, verify=False, headers=get_headers(), timeout=30)
print("Parsing %s" % (url))
parser = html.fromstring(response.text)
summary_table = parser.xpath(
'//div[contains(@data-test,"summary-table")]//tr')
summary_data = OrderedDict()
other_details_json_link = "https://query2.finance.yahoo.com/v10/finance/quoteSummary/{0}?formatted=true&lang=en-US®ion=US&modules=summaryProfile%2CfinancialData%2CrecommendationTrend%2CupgradeDowngradeHistory%2Cearnings%2CdefaultKeyStatistics%2CcalendarEvents&corsDomain=finance.yahoo.com".format(
ticker)
summary_json_response = requests.get(other_details_json_link)
try:
json_loaded_summary = json.loads(summary_json_response.text)
summary = json_loaded_summary["quoteSummary"]["result"][0]
y_Target_Est = summary["financialData"]["targetMeanPrice"]['raw']
earnings_list = summary["calendarEvents"]['earnings']
eps = summary["defaultKeyStatistics"]["trailingEps"]['raw']
datelist = []
for i in earnings_list['earningsDate']:
datelist.append(i['fmt'])
earnings_date = ' to '.join(datelist)
for table_data in summary_table:
raw_table_key = table_data.xpath(
'.//td[1]//text()')
raw_table_value = table_data.xpath(
'.//td[2]//text()')
table_key = ''.join(raw_table_key).strip()
table_value = ''.join(raw_table_value).strip()
summary_data.update({table_key: table_value})
summary_data.update({'1y Target Est': y_Target_Est, 'EPS (TTM)': eps,
'Earnings Date': earnings_date, 'ticker': ticker,
'url': url})
return summary_data
except ValueError:
print("Failed to parse json response")
return {"error": "Failed to parse json response"}
except:
return {"error": "Unhandled Error"}
if __name__ == "__main__":
argparser = argparse.ArgumentParser()
argparser.add_argument('ticker', help='')
args = argparser.parse_args()
ticker = args.ticker
print("Fetching data for %s" % (ticker))
scraped_data = parse(ticker)
print("Writing data to output file")
with open('%s-summary.json' % (ticker), 'w') as fp:
json.dump(scraped_data, fp, indent=4)
How the Scraper Has Got Executed?
Suppose the script has given the name yahoofinance.py. In case, you type a code name in the command prompt or station having a -h.
python3 yahoofinance.py -h usage: yahoo_finance.py [-h] ticker positional arguments: ticker optional arguments: -h, --help show this help message and exit
The ticker sign, often identified as the stock symbol, is utilized to recognize an organization.
To get data on Apple Inc stock, we will do the given argument:
python3 yahoofinance.py AAPL
It will make the JSON file called AAPL-summary.json in a similar folder as a script.
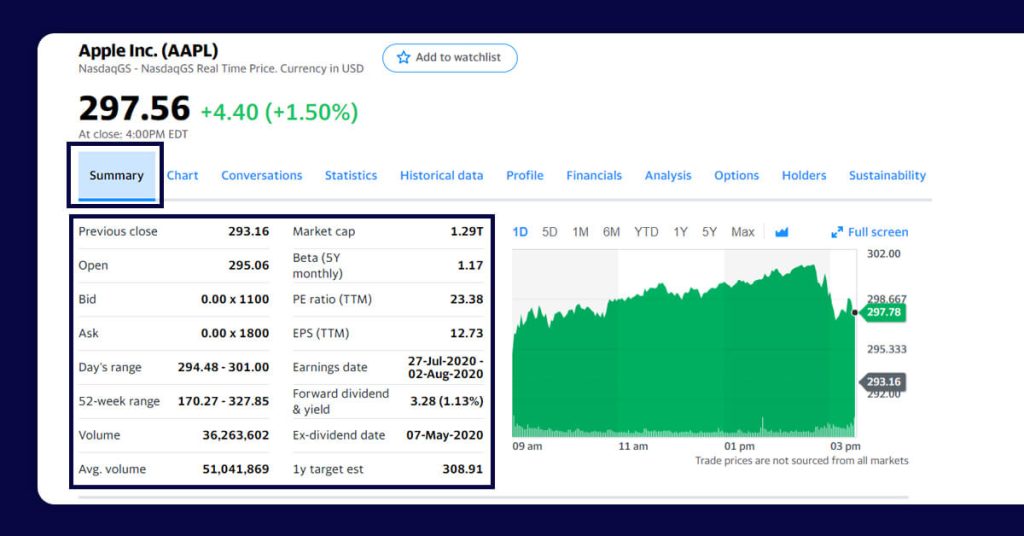
That is what output files might look like:
{
"Previous Close": "293.16",
"Open": "295.06",
"Bid": "298.51 x 800",
"Ask": "298.88 x 900",
"Day's Range": "294.48 - 301.00",
"52 Week Range": "170.27 - 327.85",
"Volume": "36,263,602",
"Avg. Volume": "50,925,925",
"Market Cap": "1.29T",
"Beta (5Y Monthly)": "1.17",
"PE Ratio (TTM)": "23.38",
"EPS (TTM)": 12.728,
"Earnings Date": "2020-07-28 to 2020-08-03",
"Forward Dividend & Yield": "3.28 (1.13%)",
"Ex-Dividend Date": "May 08, 2020",
"1y Target Est": 308.91,
"ticker": "AAPL",
"url": "http://finance.yahoo.com/quote/AAPL?p=AAPL"
}
The code would work to fetch stock market information of different companies. In case, you want to scrape Yahoo Finance historical data Python often, there are different things that you must know.
Why Do You Need to Scrape Yahoo Finance News?
In case, you’re dealing with share market data as well as require a clear, free, and reliable resource, then web scraping stock prices could be the finest option. Various company profile pages are available with a similar format, therefore if you make a script for JavaScript scrape Yahoo Finance from the Microsoft business page, you might utilize the similar script for scraping data from the Apple business page.
If anybody can’t select how to extract Yahoo financial data then the better option is to hire a skilled web data scraping company like 3i Data Scraping.
For further queries, contact 3i Data Scraping now or ask for a free quote!













What Will We Do Next?
- Our representative will contact you within 24 hours.
- We will collect all the necessary requirements from you.
- The team of analysts and developers will prepare estimation.
- We keep confidentiality with all our clients by signing NDA.



