



Web Scraping in Python using BeautifulSoup and Selenium
There are a lot of Python libraries you can utilize for data scraping as well as many online tutorials are available on how to start.
Today, we will discuss scraping e-commerce product data from dynamic pages and concentrate on how you could do it with BeautifulSoup and Selenium.
Usually, eCommerce product list pages are dynamic, producing various product details for users. For example, airline price change depending on users’ locations or products ranked by significance based on perusing behavior. The product information is generally populated using Javascript in-browser. That is where Selenium has a role to play. It could programmatically load and interact with the web pages within a browser. Then, we can use BeautifulSoup to parse the page resource and scrape required product data from the HTML elements.
This blog will show how to recover product data from pages like these automatically.
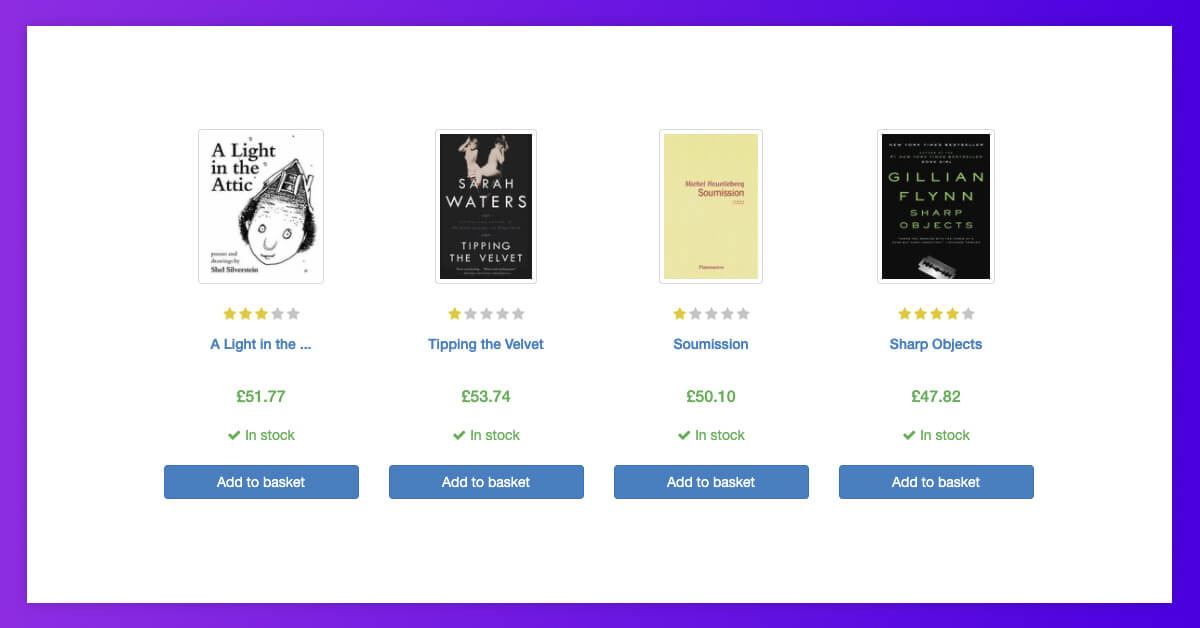
…for a clean and useable format for use and analysis.
Why do this? Knowing your competitors, price comparisons across different retailers, and analyzing the market trends are only some practical applications.

To get an element, we could filter through its tag or attribute name and value.
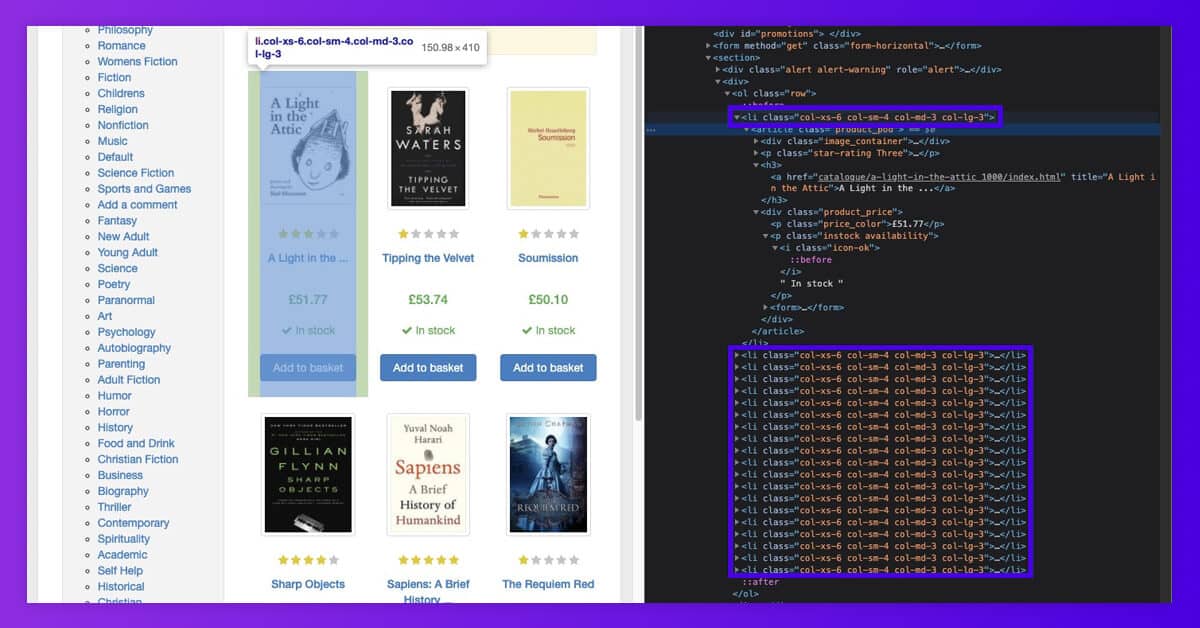
For scraping all product names on the initial page of the fictional bookstore, let’s recognize which elements they got stored in. This looks like the text is reliably stored in <h3> tag.

Soup.find() get the initial element that matches our filter: the tag name matches ‘h3’.
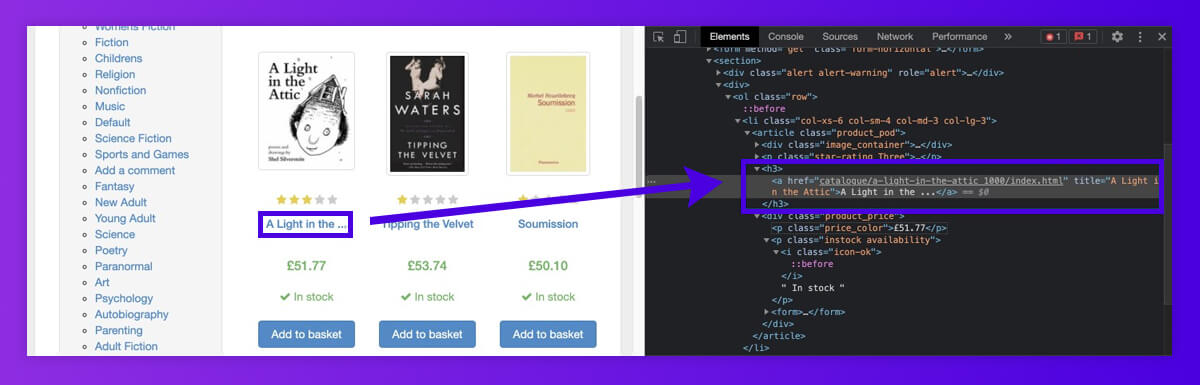
Adding .string returns the element texts only.
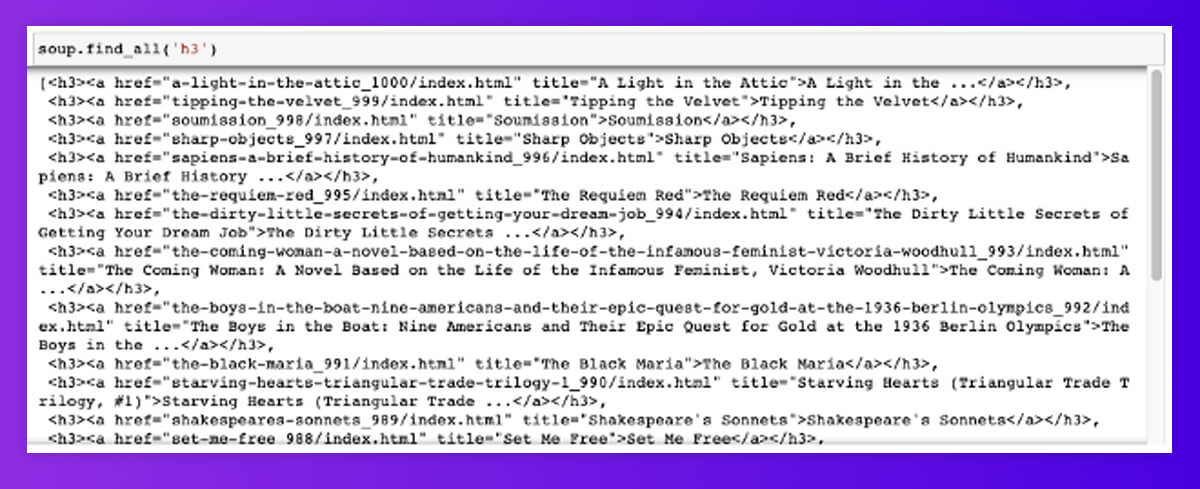
Soup.find_all() gets all the elements that match our filter and returns them within the list. Note: soup.find_all() and soup() would function similarly in case you’re a brevity fan.
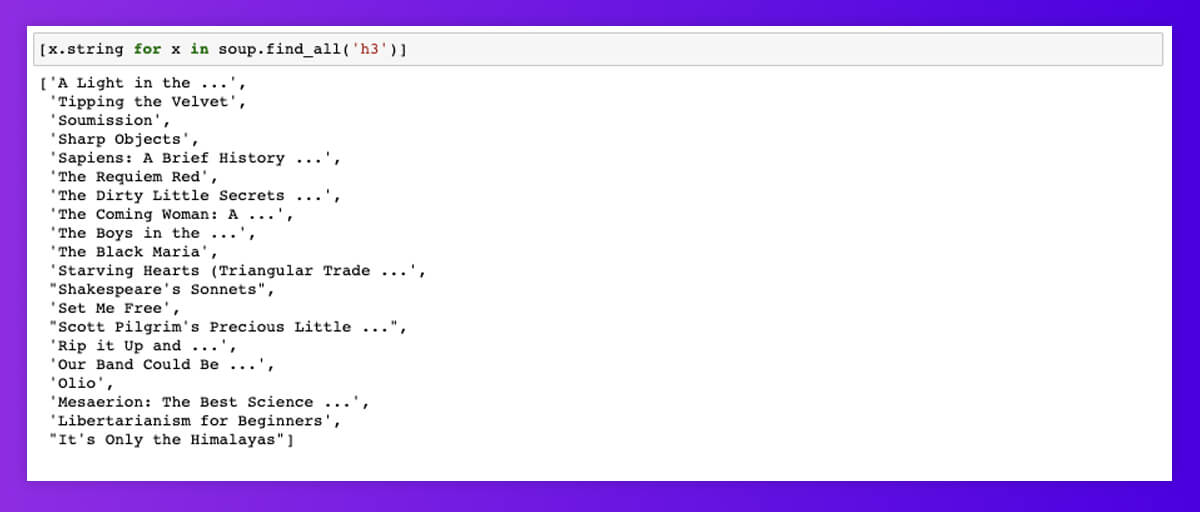
We are finally looping through. String in the list comprehension returns the elements’ texts. Now, we have got the list of 20 products’ names!
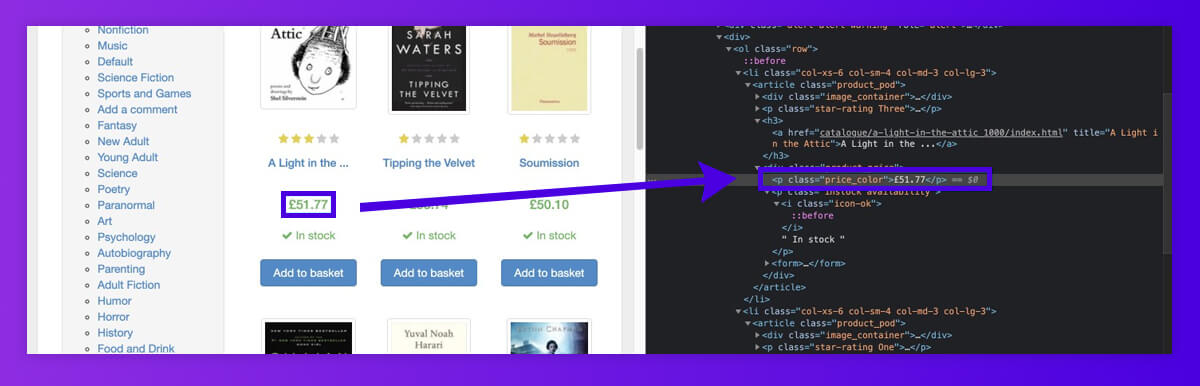
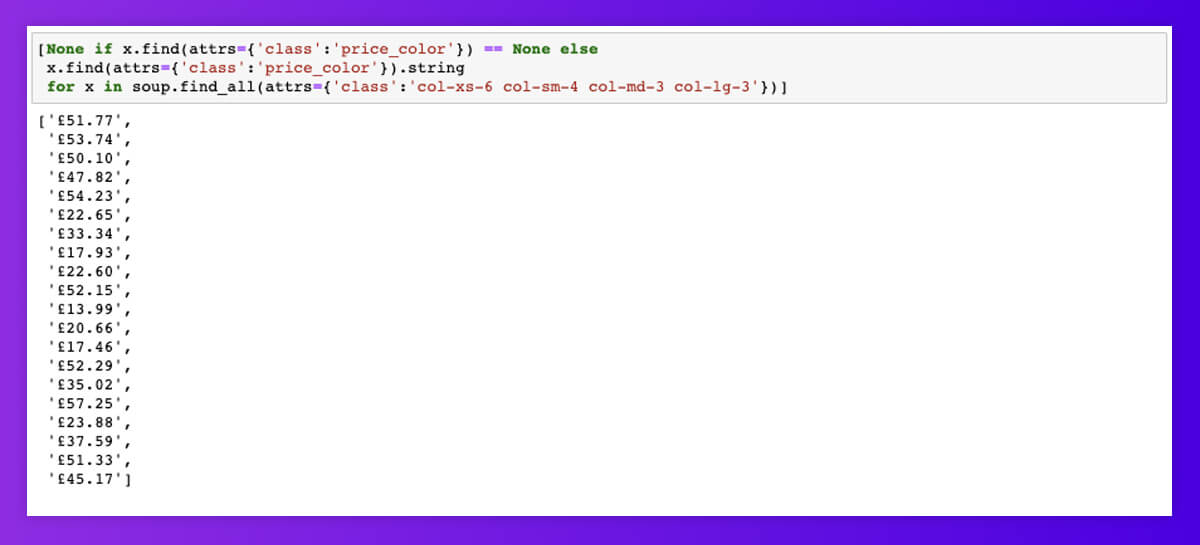
A similar can be made with all the product details. To find all product prices, we have filtered through attribute names called ‘class’ and attribute values called ‘price_color.’
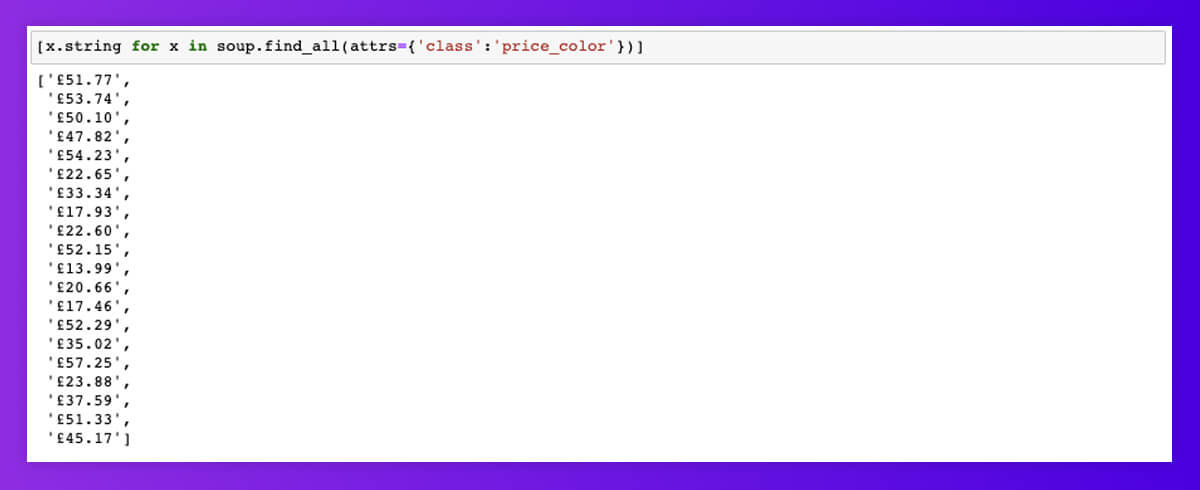
You can also stop here as wella s focus on lists of various product details, and it might work very well for websites with clean HTML. However, e-commerce websites are not always explicit, and troubleshooting for the exceptions could be the most time-consuming part of the procedure.
It is the most general exception we have encountered.
What occurs when elements are lost for specific products? For instance, if any product is provisionally unavailable and there are no tags having prices for the product. Rather than having null values in a list, we might get the price list, which is shorter than a list of different product names, and risk getting incorrect pricing against the products.
To avoid that, we found it best to first filter to the outer elements, which contain all the product data, then, within every outer element, get particular inner elements like the product’s name, pricing, etc. We could include the condition for returning the null value if the inner elements are missing from the product tiles. It will ensure all the product data is in the same order within our lists.
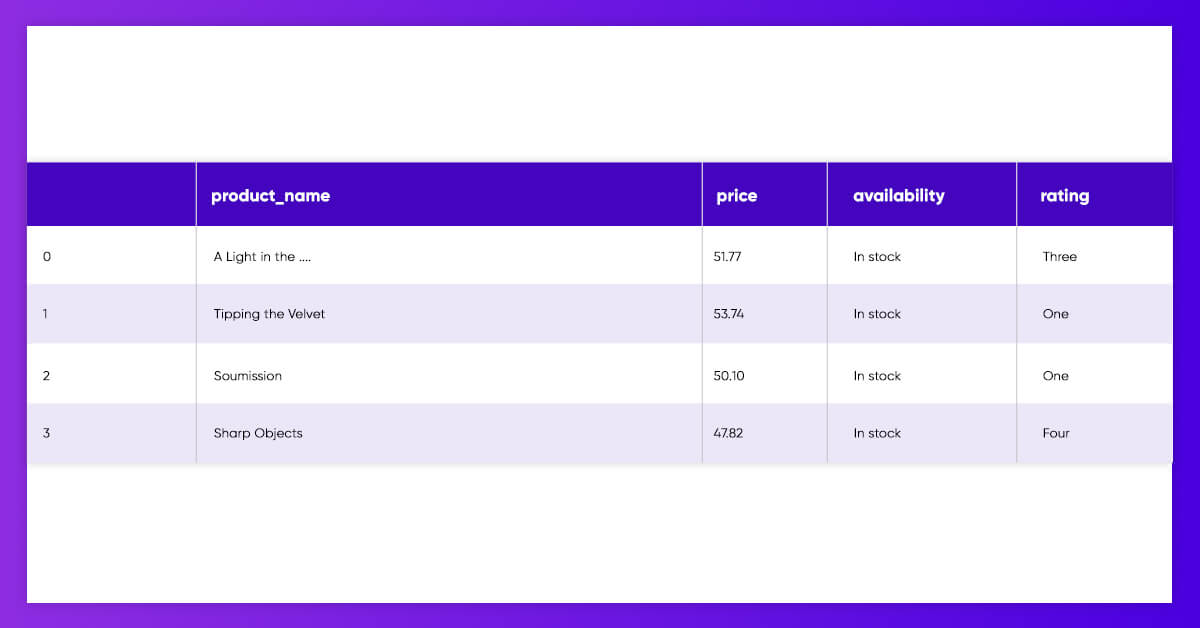
We may put the lists of various product data straight in the Pandas DataFrame and name every column.
For all ways you can navigate the elements, see BeautifulSoup documentation.
It is also a perfect time for preprocessing some features, including removing the currency symbols and the whitespaces around the text.
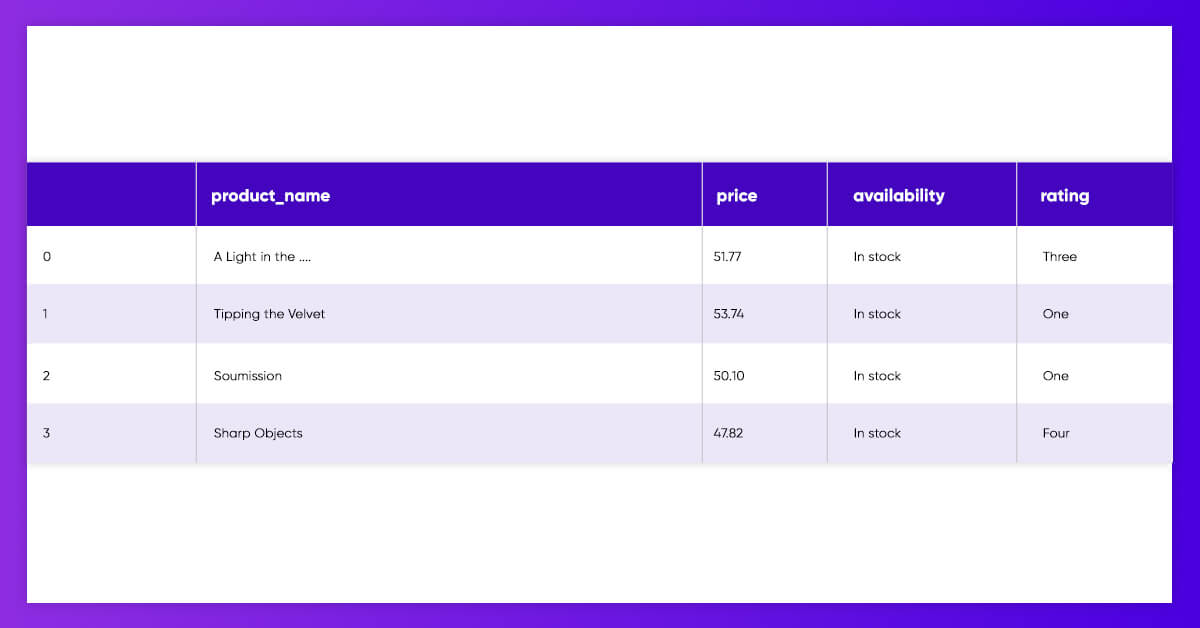
To get it easily done, we may put that in the function to scrape the page having a single line of code.
















