Some of the best tips for scraping the web
You must follow best practices when working on a scraping project for a business use case. These best practices include both programmatic and non-programmatic aspects. Also, following best practices helps maintain an ethical path. This article provides tips on how to use web scraping most effectively.
Our achievements in the field of business digital transformation.





Companies that require a lot of data to make wise business decisions employ web scraping. Web scrapers capture billions of data from numerous sources daily using sophisticated automation. To use and review the information, they gather it in an unstructured format, like HTML code, and then convert it into a structured format, like JSON.
We will talk about some of the best practices and ideas. These practices enable any business to manage any web scraping-related issues.
Some scraping strategies
1. Plan before you scrape

Why do you need data? Although the answer may seem simple, choosing what data you should get is vital. Like any project, web scraping operations run much more smoothly if you have a clear plan before you start.
Where will you then get the data? Examining your data sources can help you create or purchase the best program for the job because the scraping tool needs to be appropriate for the websites it needs to visit.
Moreover, how will you make use of the data you have collected? You could employ software to process data or send it via a complex pipeline. Your first step in defining the structure and file format for the collected data will be to identify the answer.
You must sort out a few other issues depending on your goals. The adage “measure twice, cut once” applies to web scraping; that much is certain.
2. Act more human

Bots move lighting fast across the page without interfering with anything else. They are simple to identify and block. It would be best to observe a website visitor’s behavior to define whether it is a human or a robot.
People behave differently, giving you much freedom while programming here. It will help if you educate the scraper to behave more like a frequent visitor. Here are some things we advise you to do:
- Add sporadic periods of inactivity to make it appear like someone is reading the text on the page. A delay of 5 to 10 seconds is adequate.
- Go through pages in a tree-like fashion. When scraping multiple child pages, always return to the parent page before continuing. It will simulate clicking on one page, returning to it, clicking on the next page, and so forth.
- Make the bot sometimes click on strange items.
The website can keep track of and track your bot’s behavior. Thus, it needs to behave in a specific way.
3. Follow a different crawling pattern.
Some intrinsic variations exist between how human users and bots consume data from a website.
Bots are quick yet predictable, whereas real humans are slow and unreliable. An anti-scraping tool uses this fact to prevent web scraping on the site. Including random behaviors that perplex anti-scraping technologies are a good idea.
4. IP Rotation
In most cases, websites use IP addresses to identify scrapers. It uses multiple alternative IP addresses to avoid being blocked and prevent any one IP address from being blacklisted. You can use an IP rotation service, such as 3iData Scraping, or other proxy services to route your requests via various IP addresses to prevent sending all of your queries through the same IP address. You can easily scrape the vast majority of websites with it.
5. Scraping the web when rotating user agent
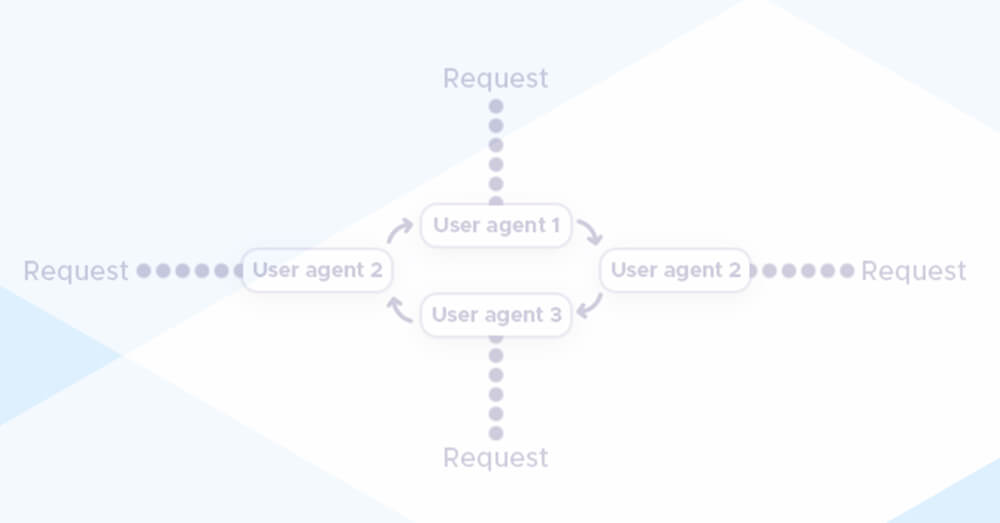
There are many websites where you can get different user-agent strings. User-agent rotation is implemented by manually changing the headers or creating a function that updates the user-agent list each time the web scraping script launches. It can be applied similarly to the previous function to retrieve IP addresses.
Be sure that your user agents are updated, either manually or automatically. Because new browser versions come out so frequently, it is easier to recognize an outdated user-agent string and for servers to reject requests from such user agents.
6. Web page object selection

A web page’s objects can choose in a few different ways. The two most common ways to select page elements are CSS selectors and XPATH navigation. You are presumably already aware of the structure and nesting of tags.
The fact that each browser’s XPATH engine is unique makes utilizing XPATH locators unreliable, which is one of the key disadvantages. Additionally, even if you use the same browser for scraping, XPATH may change unexpectedly and update the web page depending on how you map the location.
CSS selectors provide a more reliable method of discovering things on a website page. Applications built with CSS are generally more user-friendly. Thus, writing code, discussing it, and enlisting others to help maintain the script will be more accessible.
7. Solving CAPTCHAs
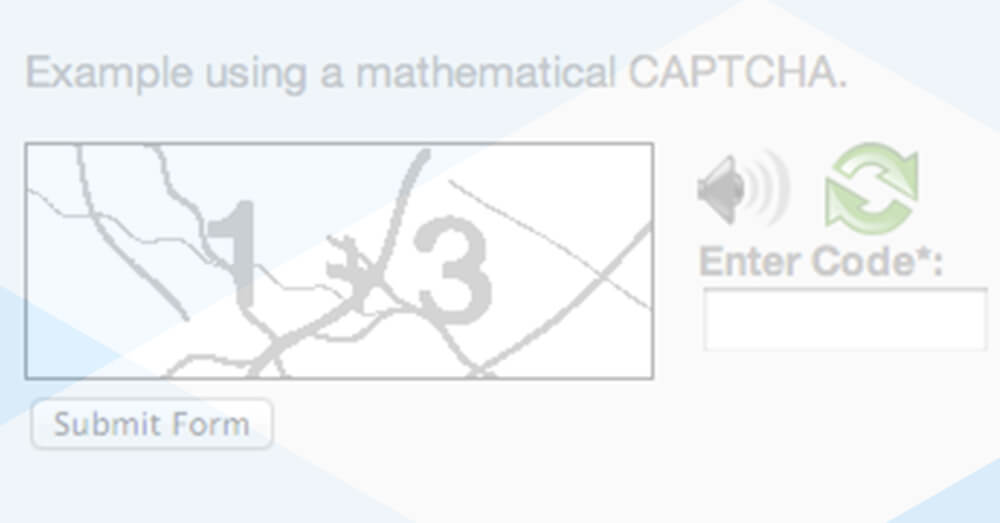
Simple programs can be blocked by monitoring “user activity and storing it in cookies. A CAPTCHA is presented to the user to complete if the behavior of the ‘behavior ser’ appears suspicious. This method does not block potential users, but most web scrapers do. Utilize a problem-solving script to extract data that use CAPTCHAs for web scraping.
An open-source Optical Character Recognition (OCR) engine might be the simplest method to solve a CAPTCHA, depending on its kind. Some of the most well-liked technologies include Tesseract, GOCR, and Ocrad.
You can always use a CAPTCHA-solving service. A tesseract is an easy command-line tool to include in a web scraping script. While developing a Python web scraping application, PyTesseract helps read CAPTCHA images.
8. Make an URL list
When you begin a scraping activity, you will probably develop a list of helpful data URLs. Here is one idea: create a list and mark any links you have already crawled rather than just providing the URLs to the scraper. You can optionally leave the URL on the data you collected for clarity.
It is simple: even if your computer malfunctions or unforeseen circumstances occur, you will still have access to your existing data, so you won’t have to re-scrape it again.
Writing a script for data extraction record keeping is our recommendation. You will need assistance to keep up with the bot when updating the list because it is a busy job.
9. Essential cache pages
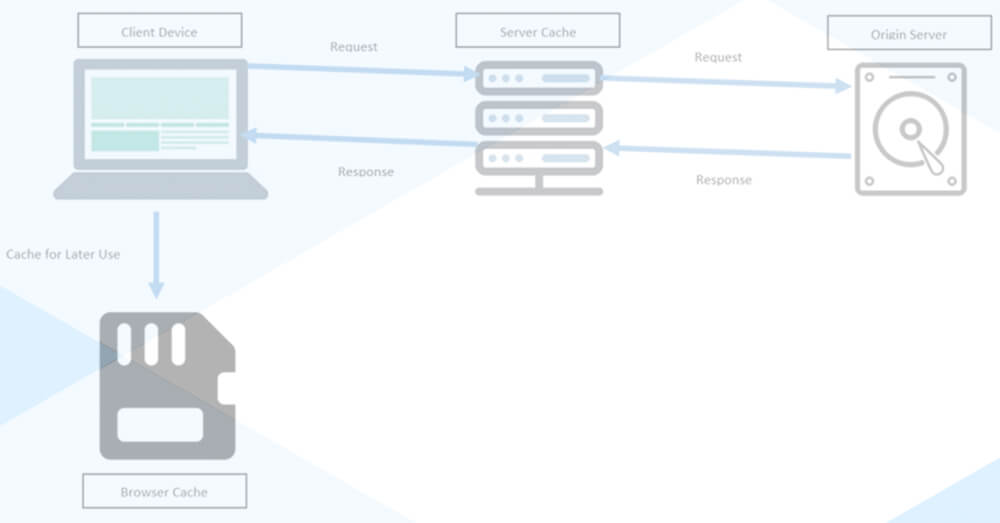
You can find more information on the scraped pages. The best way to visit a website is to cache and save all the data.
Even the most advanced web scrapers will get the data on their first try, and even if they do, it will be useless. If you need to extract valuable information from the HTML, capture the HTML once and save it.
For instance, a product page can be cached, making it always accessible. Consider the cost if you need the product requirements today. The data has already been gathered and is awaiting the process.
It works for static information, but be careful! Since the cached version will quickly become outdated, you must continue extracting new data if you want stock prices.
10. Cache to avoid unnecessary requests

The time it takes to complete a scrape can be reduced if you know what pages your web scraper has already visited.
You can reduce the requests you need to make by caching the pages. Caching HTTP requests and answers is a good idea. You can write it to a file if you need to execute the scrape. Otherwise, you can write it to a database.
Constantly improve the scraper’s logic to reduce the number of requests it makes. It is vital to optimizing scraper logic to avoid making unnecessary requests.
11. Use a Headless Browser

The most complex websites to scrape may find tiny clues that a genuine user is making the request, such as web fonts, extensions, browser cookies, and JavaScript execution. It would help if you used your headless browser to scrape these pages.
You may create a program to operate a genuine web browser that is precisely like what a real user would use to avoid detection using tools like Selenium and Puppeteer. Only use these tools if you are restricted since you are not using a genuine browser because most websites only need a basic GET request! When it is vital, you should employ these tools for web scraping. While making Puppeteer or Selenium undetectable takes some effort, it is the most efficient approach to scrape websites that would otherwise be quite challenging.
12. Be careful when logging in
The data you require hides behind a login page. Social media scraping platforms come to mind. Yes, accessing a small amount of content without creating an account is possible, but doing so needs more work. Moreover, content may only be accessible to those on your friends’ list or group.
In other words, you might have to log in, which has some issues.
All registered users must accept the website’s Terms of Service. There may be a provision in these terms that expressly restricts the use of bots, automated programs, or web scrapers.
Furthermore, websites pay more attention to cookies sent by logged-in users than anonymous visitors. Therefore, more people will observe your bot. Your scraper is even more likely to be blacklisted if it engages in explicit bot behavior or sets telling cookies.
What you ought to do is,
- By carefully reading them, ensure you are not violating the Terms of Service.
- Be careful to adhere to the other requests in this article, particularly those dealing with proxies, human behavior, JS rendering, and request headers.
13. Using the cached web content of Google,
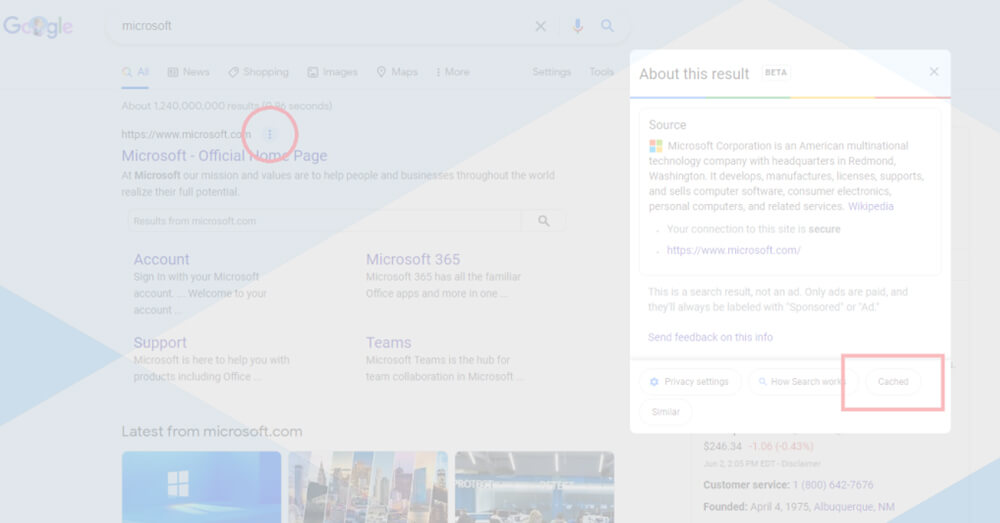
You no longer need to worry about how to scrape a website without gaining access to its servers. Use Google’s cached pages site material for covert scraping, depending on how recent the data needs. Google scrapes the web when it indexes it; fortunately for us, it also makes cached content available.
Keeping web page servers manageable is easy by scraping cached content. Google will probably crawl your site more frequently if it is updated frequently. The cached content is sometimes a few hours old. If you scrape the website’s cached content, you will not get the most recent data, but you will not have to worry about any security measures the actual server might have implemented.
You can use cached web content to collect data from websites by searching Google for the online page you want to scrape and choosing the green arrow next to the link to the site. You may rapidly scrape the data and view the date of the most recent snapshot using the text-only version.
14. Respect the website and its users

Similarly, we strongly recommend respecting the website you are scraping.
It will also specify how often you can scrape the website. To find out which sites you may or cannot scrape, read the robots.txt file that the website’s owner has created.
A website can use a part of its bandwidth during intensive scraping. Other users will have a bad experience with the website as a result. It would also be helpful if you show consideration for the other website visitors.
It is a courtesy for web scraping. If you break such guidelines, your IP address can be blacklisted.
Conclusion
Web scraping is gradually gaining popularity as a tool for business intelligence and research, so it is vital to manage it precisely.
Although there is no full-proof method for web scraping, some thinking can help you get the most significant results in peak times. It is essential when scraping smaller websites because they need the web hosting facilities of larger companies.
If you are looking for the best strategies for web scraping, you should follow 3iData Scraping. We are always available for your queries!













What Will We Do Next?
- Our representative will contact you within 24 hours.
- We will collect all the necessary requirements from you.
- The team of analysts and developers will prepare estimation.
- We keep confidentiality with all our clients by signing NDA.



